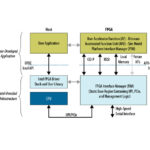
Unidade funcional do acelerador de loopback nativo de intel (AFU)

Sobre este documento
Convencións
Táboa 1. Convencións do documento
| Convenio | Descrición |
| # | Precede a un comando que indica que o comando debe introducirse como root. |
| $ | Indica que se debe introducir un comando como usuario. |
| Este tipo de letra | Filenomes, comandos e palabras clave están impresos neste tipo de letra. As liñas de comando longas están impresas neste tipo de letra. Aínda que as liñas de comando longas poden envolverse na seguinte liña, o retorno non forma parte do comando; non prema Intro. |
| Indica que o texto do marcador de posición que aparece entre os corchetes angulares debe ser substituído por un valor adecuado. Non introduza os corchetes angulares. |
Acrónimos
Táboa 2. Siglas
| Acrónimos | Expansión | Descrición |
| AF | Función Acelerador | Imaxe compilada do acelerador de hardware implementado en lóxica FPGA que acelera unha aplicación. |
| AFU | Unidade Funcional Acelerador | Acelerador de hardware implementado en lóxica FPGA que descarga unha operación computacional para unha aplicación da CPU para mellorar o rendemento. |
| API | Interfaz de programación de aplicacións | Un conxunto de definicións de subrutinas, protocolos e ferramentas para crear aplicacións de software. |
| ASE | Ambiente de simulación AFU | Entorno de co-simulación que permite utilizar a mesma aplicación host e AF nun ambiente de simulación. ASE forma parte do Intel® Acceleration Stack para FPGA. |
| CCI-P | Interface Core Cache | CCI-P é a interface estándar que usan as AFU para comunicarse co host. |
| CL | Liña de caché | Liña de caché de 64 bytes |
| DFH | Cabeceira da función do dispositivo | Crea unha lista ligada de cabeceiras de funcións para ofrecer unha forma extensible de engadir funcións. |
| FIM | Xestor de interfaces FPGA | O hardware FPGA que contén a unidade de interface FPGA (FIU) e interfaces externas para memoria, redes, etc.
A función de acelerador (AF) interactúa co FIM no tempo de execución. |
| FIU | Unidade de interface FPGA | FIU é unha capa de interface de plataforma que actúa como ponte entre interfaces de plataforma como PCIe*, UPI e interfaces do lado AFU como CCI-P. |
| continuou… | ||
Intel Corporation. Todos os dereitos reservados. Intel, o logotipo de Intel e outras marcas de Intel son marcas comerciais de Intel Corporation ou das súas subsidiarias. Intel garante o rendemento dos seus produtos FPGA e semicondutores segundo as especificacións actuais de acordo coa garantía estándar de Intel, pero resérvase o dereito de facer cambios en calquera produto e servizo en calquera momento e sen previo aviso. Intel non asume ningunha responsabilidade ou responsabilidade derivada da aplicación ou uso de calquera información, produto ou servizo descrito aquí, salvo que Intel o acorde expresamente por escrito. Recoméndase aos clientes de Intel que obteñan a versión máis recente das especificacións do dispositivo antes de confiar en calquera información publicada e antes de facer pedidos de produtos ou servizos. *Outros nomes e marcas poden ser reclamados como propiedade doutros.
| Acrónimos | Expansión | Descrición |
| MPF | Fábrica de propiedades da memoria | O MPF é un bloque básico de construción (BBB) que as AFU poden usar para proporcionar operacións de conformación de tráfico CCI-P para transaccións coa FIU. |
| Msg | Mensaxe | Mensaxe: unha notificación de control |
| NLB | Loopback nativo | O NLB realiza lecturas e escrituras na ligazón CCI-P para probar a conectividade e o rendemento. |
| RdLine_I | A liña de lectura non é válida | Solicitude de lectura de memoria, coa indicación da caché FPGA definida como non válida. A liña non está almacenada na FPGA, pero pode provocar a contaminación da caché da FPGA.
Nota: O caché tag rastrexa o estado da solicitude de todas as solicitudes pendentes en Intel Ultra Path Interconnect (Intel UPI). Polo tanto, aínda que RdLine_I está marcado como non válido ao finalizar, consume a caché tag temporalmente para rastrexar o estado da solicitude a través de UPI. Esta acción pode provocar o desaloxo dunha liña de caché, o que provoca a contaminación da caché. O adiantotagO uso de RdLine_I é que non o rastrexa o directorio da CPU; polo tanto, impide fisgonear desde a CPU. |
| RdLine-S | Ler a liña compartida | Solicitude de lectura de memoria coa suxestión da caché FPGA definida como compartida. Inténtase mantelo na caché da FPGA nun estado compartido. |
| WrLine_I | A liña de escritura non é válida | Solicitude de escritura de memoria, coa suxestión da caché FPGA definida como Non válida. A FIU escribe os datos sen intención de manter os datos na caché FPGA. |
| WrLine_M | Liña de escritura modificada | Solicitude de escritura de memoria, coa suxestión da caché FPGA definida como Modificada. A FIU escribe os datos e déixaos na caché da FPGA nun estado modificado. |
Glosario de aceleración
Táboa 3. Pila de aceleración para CPU Intel Xeon® con Glosario de FPGA
| Prazo | Abreviatura | Descrición |
| Intel Acceleration Stack para CPU Intel Xeon® con FPGA | Pila de aceleración | Unha colección de software, firmware e ferramentas que proporciona conectividade optimizada para o rendemento entre unha FPGA Intel e un procesador Intel Xeon. |
| Tarxeta de aceleración programable Intel FPGA (Intel FPGA PAC) | Intel FPGA PAC | Tarxeta aceleradora PCIe FPGA. Contén un FPGA Interface Manager (FIM) que se empareja cun procesador Intel Xeon a través do bus PCIe. |
A Unidade Funcional Native Loopback Accelerator (AFU)
AFU Loopback nativo (NLB) finalizadoview
- A NLB sampAs AFU comprenden un conxunto de Verilog e System Verilog files para probar as lecturas e escrituras da memoria, o ancho de banda e a latencia.
- Este paquete inclúe tres AFU que podes construír a partir da mesma fonte RTL. A túa configuración do código fonte RTL crea estas AFU.
O NLB Sample Función de aceleración (AF)
O $OPAE_PLATFORM_ROOT/hw/sampo directorio les almacena o código fonte dos seguintes NLBampas AFU:
- nlb_mode_0
- nlb_mode_0_stp
- nlb_mode_3
Nota: O $DCP_LOC/hw/sampo directorio les almacena os NLB sample AFUs código fonte para o paquete de versión 1.0.
Para entender os NLB sampA estrutura do código fonte da AFU e como crealo, consulte unha das seguintes guías de inicio rápido (dependendo de que Intel FPGA PAC estea a usar):
- Se está a usar Intel PAC con Intel Arria® 10 GX FPGA, consulte a tarxeta de aceleración IntelProgrammable con Intel Arria 10 GX FPGA.
- Se está a usar Intel FPGA PAC D5005, consulte a Guía de inicio rápido de Intel Acceleration Stack para a tarxeta de aceleración programable Intel FPGA D5005.
O paquete de versión ofrece os seguintes tres sampas AF:
- Modo NLB 0 AF: require a utilidade hello_fpga ou fpgadiag para realizar a proba lpbk1.
- Modo NLB 3 AF: require a utilidade fpgadiag para realizar as probas de trupt, lectura e escritura.
- Modo NLB 0 stp AF: require a utilidade hello_fpga ou fpgadiag para realizar a proba lpbak1.
Nota: O nlb_mode_0_stp é o mesmo AFU que nlb_mode_0 pero coa función de depuración Signal Tap activada.
As utilidades fpgadiag e hello_fpga axudan ao AF adecuado a diagnosticar, probar e informar sobre o hardware FPGA.
Intel Corporation. Todos os dereitos reservados. Intel, o logotipo de Intel e outras marcas de Intel son marcas comerciais de Intel Corporation ou das súas subsidiarias. Intel garante o rendemento dos seus produtos FPGA e semicondutores segundo as especificacións actuais de acordo coa garantía estándar de Intel, pero resérvase o dereito de facer cambios en calquera produto e servizo en calquera momento e sen previo aviso. Intel non asume ningunha responsabilidade ou responsabilidade derivada da aplicación ou uso de calquera información, produto ou servizo descrito aquí, salvo que Intel o acorde expresamente por escrito. Recoméndase aos clientes de Intel que obteñan a versión máis recente das especificacións do dispositivo antes de confiar en calquera información publicada e antes de facer pedidos de produtos ou servizos. *Outros nomes e marcas poden ser reclamados como propiedade doutros.
Figura 1. Loopback nativo (nlb_lpbk.sv) Envoltorio de nivel superior

Táboa 4. NLB Files
| File Nome | Descrición |
| nlb_lpbk.sv | Envoltorio de nivel superior para NLB que instancia o solicitante e o árbitro. |
| árbitro.sv | Instancia a proba AF. |
| solicitante.sv | Acepta solicitudes do árbitro e formatea as solicitudes segundo a especificación CCI-P. Tamén implementa o control de fluxo. |
| nlb_csr.sv | Implementa uns rexistros de control e estado (CSR) de lectura/escritura de 64 bits. Os rexistros admiten lecturas e escrituras de 32 e 64 bits. |
| nlb_gram_sdp.sv | Implementa unha memoria RAM xenérica de dobre porto cun porto de escritura e un porto de lectura. |
NLB é unha implementación de referencia dunha AFU compatible con Intel Acceleration Stack para CPU Intel Xeon con FPGAs Core Cache Interface (CCI-P) Manual de referencia. A función principal de NLB é validar a conectividade do host usando diferentes patróns de acceso á memoria. NLB tamén mide o ancho de banda e a latencia de lectura/escritura. A proba de ancho de banda ten as seguintes opcións:
- 100% lido
- 100% escribe
- 50% le e 50% escribe
Información relacionada
- Guía de inicio rápido de Intel Acceleration Stack para tarjeta de aceleración programable Intel con Arria 10 GX FPGA
- Pila de aceleración para CPU Intel Xeon con FPGA Core Cache Interface (CCI-P) Manual de referencia
- Guía de inicio rápido de Intel Acceleration Stack para tarjeta de aceleración programable Intel FPGA D5005
Control de bucle nativo e descricións do rexistro de estado
Táboa 5. Nomes, enderezos e descricións da RSE
| Enderezo de byte (OPAE) | Palabra Enderezo (CCI-P) | Acceso | Nome | Anchura | Descrición |
| 0x0000 | 0x0000 | RO | DFH | 64 | Cabeceira da función do dispositivo AF. |
| 0x0008 | 0x0002 | RO | AFU_ID_L | 64 | ID AF baixa. |
| 0x0010 | 0x0004 | RO | AFU_ID_H | 64 | ID AF alta. |
| 0x0018 | 0x0006 | Rsvd | CSR_DFH_RSVD0 | 64 | Obrigatorio Reservado 0. |
| 0x0020 | 0x0008 | RO | CSR_DFH_RSVD1 | 64 | Obrigatorio Reservado 1. |
| 0x0100 | 0x0040 | RW | CSR_SCRATCHPAD0 | 64 | Rexistro Scratchpad 0. |
| 0x0108 | 0x0042 | RW | CSR_SCRATCHPAD1 | 64 | Rexistro Scratchpad 2. |
| 0x0110 | 0x0044 | RW | CSR_AFU_DSM_BASE L | 32 | 32 bits inferiores do enderezo base AF DSM. Os 6 bits inferiores son 4×00 porque o enderezo está aliñado co tamaño da liña de caché de 64 bytes. |
| 0x0114 | 0x0045 | RW | CSR_AFU_DSM_BASE H | 32 | 32 bits superiores do enderezo base AF DSM. |
| 0x0120 | 0x0048 | RW | CSR_SRC_ADDR | 64 | Iniciar o enderezo físico para o búfer de orixe. Todas as solicitudes de lectura teñen como destino esta rexión. |
| 0x0128 | 0x004A | RW | CSR_DST_ADDR | 64 | Iniciar o enderezo físico para o búfer de destino. Todas as solicitudes de escritura teñen como destino esta rexión |
| 0x0130 | 0x004C | RW | CSR_NUM_LINES | 32 | Número de liñas de caché. |
| 0x0138 | 0x004E | RW | CSR_CTL | 32 | Controla o fluxo de proba, o inicio, a parada e a forza de finalización. |
| 0x0140 | 0x0050 | RW | CSR_CFG | 32 | Configura os parámetros de proba. |
| 0x0148 | 0x0052 | RW | CSR_INACT_THRESH | 32 | Límite do limiar de inactividade. |
| 0x0150 | 0x0054 | RW | CSR_INTERRUPT0 | 32 | SW asigna Interrupt APIC ID e Vector ao dispositivo. |
| Mapa de compensación DSM | |||||
| 0x0040 | 0x0010 | RO | DSM_STATUS | 32 | Estado da proba e rexistro de erros. |
Táboa 6. Campos de bits de CSR con Examples
Esta táboa enumera os campos de bits CSR que dependen do valor do CSR_NUM_LINES, . No example a continuación = 14.
| Nome | Campo de bits | Acceso | Descrición |
| CSR_SRC_ADDR | [63:] | RW | O enderezo aliñado de 2^(N+6)MB apunta ao inicio do búfer de lectura. |
| [-1:0] | RW | 0x0. | |
| CSR_DST_ADDR | [63:] | RW | O enderezo aliñado de 2^(N+6)MB apunta ao inicio do búfer de escritura. |
| [-1:0] | RW | 0x0. | |
| CSR_NUM_LINES | [31:] | RW | 0x0. |
| continuou… | |||
| Nome | Campo de bits | Acceso | Descrición |
| [-1:0] | RW | Número de liñas de caché para ler ou escribir. Este limiar pode ser diferente para cada AF de proba.
Nota: Asegúrese de que os búfers de orixe e destino sexan o suficientemente grandes como para acomodar liñas de caché. CSR_NUM_LINES debe ser inferior ou igual a . |
|
| Para os seguintes valores, supoña = 14. A continuación, CSR_SRC_ADDR e CSR_DST_ADDR aceptan 2^20 (0x100000). | |||
| CSR_SRC_ADDR | [31:14] | RW | Enderezo aliñado de 1 MB. |
| [13:0] | RW | 0x0. | |
| CSR_DST_ADDR | [31:14] | RW | Enderezo aliñado de 1 MB. |
| [13:0] | RW | 0x0. | |
| CSR_NUM_LINES | [31:14] | RW | 0x0. |
| [13:0] | RW | Número de liñas de caché para ler ou escribir. Este limiar pode ser diferente para cada AF de proba.
Nota: Asegúrese de que os búfers de orixe e destino sexan o suficientemente grandes como para acomodar liñas de caché. |
|
Táboa 7. Campos adicionais de bits de CSR
| Nome | Campo de bits | Acceso | Descrición |
| CSR_CTL | [31:3] | RW | Reservado. |
| [2] | RW | Forzar a finalización da proba. Escribe a marca de finalización da proba e outros contadores de rendemento en csr_stat. Despois de forzar a finalización da proba, o estado do hardware é idéntico ao dunha finalización da proba non forzada. | |
| [1] | RW | Inicia a execución da proba. | |
| [0] | RW | Reinicio de proba baixo activo. Cando é baixo, todos os parámetros de configuración cambian aos seus valores predeterminados. | |
| CSR_CFG | [29] | RW | cr_interrupt_testmode proba as interrupcións. Xera unha interrupción ao final de cada proba. |
| [28] | RW | cr_interrupt_on_error envía unha interrupción cando se produce un erro | |
| detección. | |||
| [27:20] | RW | cr_test_cfg configura o comportamento de cada modo de proba. | |
| [13:12] | RW | cr_chsel selecciona a canle virtual. | |
| [10:9] | RW | cr_rdsel configura o tipo de solicitude de lectura. As codificacións teñen o | |
| valores válidos seguintes: | |||
| • 1'b00: RdLine_S | |||
| • 2'b01: RdLine_I | |||
| • 2'b11: Modo mixto | |||
| [8] | RW | cr_delay_en permite a inserción aleatoria de atrasos entre as solicitudes. | |
| [6:5] | RW | Configura o modo de proba, cr_multiCL-len. Os valores válidos son 0,1 e 3. | |
| [4:2] | RW | cr_mode, configura o modo de proba. Os seguintes valores son válidos: | |
| • 3'b000: LPBK1 | |||
| • 3'b001: Ler | |||
| • 3'b010: Escribe | |||
| • 3'b011: TRPUT | |||
| continuou… | |||
| Nome | Campo de bits | Acceso | Descrición |
| Para obter máis información sobre o modo de proba, consulte Modos de proba tema a continuación. | |||
| [1] | RW | c_cont selecciona o rollover ou a terminación da proba.
• Cando 1'b0, a proba remata. Actualiza o estado CSR cando Alcanzouse o reconto de CSR_NUM_LINES. • Cando é 1'b1, a proba pasa ao enderezo de inicio despois de que alcance o reconto de CSR_NUM_LINES. No modo de rollover, a proba remata só en caso de erro. |
|
| [0] | RW | cr_wrthru_en cambia entre os tipos de solicitude WrLine_I e Wrline_M.
• 1'b0: WrLine_M • 1'b1: WrLine_I |
|
| CSR_INACT_THRESHOLD | [31:0] | RW | Límite do limiar de inactividade. Detecta a duración das paradas durante unha proba. Conta o número de ciclos inactivos consecutivos. Se a inactividade conta
> CSR_INACT_THRESHOLD, non se envían solicitudes nin respostas recibido e o sinal inact_timeout está configurado. Escribir 1 en CSR_CTL[1] activa este contador. |
| CSR_INTERRUPT0 | [23:16] | RW | Número de vector de interrupción para o dispositivo. |
| [15:0] | RW | apic_id é o APIC OD para o dispositivo. | |
| DSM_STATUS | [511:256] | RO | Erro ao verter o formulario Modo de proba. |
| [255:224] | RO | Fin de sobrecarga. | |
| [223:192] | RO | Comeza a sobrecarga. | |
| [191:160] | RO | Número de Escrituras. | |
| [159:128] | RO | Número de lecturas. | |
| [127:64] | RO | Número de reloxos. | |
| [63:32] | RO | Rexistro de erros de proba. | |
| [31:16] | RO | Compara e intercambia contador de éxito. | |
| [15:1] | RO | ID único para cada escritura de estado de DSM. | |
| [0] | RO | Bandeira de finalización da proba. |
Modos de proba
CSR_CFG[4:2] configura o modo de proba. As seguintes catro probas están dispoñibles:
- LPBK1: Esta é unha proba de copia de memoria. O AF copia CSR_NUM_LINES do búfer de orixe ao búfer de destino. Ao rematar a proba, o software compara os búfers de orixe e destino.
- Ler: Esta proba enfatiza o camiño de lectura e mide o ancho de banda ou a latencia de lectura. O AF le CSR_NUM_LINES a partir do CSR_SRC_ADDR. Esta é só unha proba de ancho de banda ou latencia. Non verifica os datos lidos.
- Escribe: Esta proba enfatiza o camiño de escritura e mide o ancho de banda ou a latencia de escritura. O AF le CSR_NUM_LINES a partir do CSR_SRC_ADDR. Esta é só unha proba de ancho de banda ou latencia. Non verifica os datos escritos.
- TRUPO: Esta proba combina as lecturas e as escrituras. Le CSR_NUM_LINES a partir da localización CSR_SRC_ADDR e escribe CSR_NUM_LINES en CSR_SRC_ADDR. Tamén mide o ancho de banda de lectura e escritura. Esta proba non verifica os datos. As lecturas e as escrituras non teñen dependencias
A seguinte táboa mostra as codificacións CSR_CFG para as catro probas. Esta táboa establece e CSR_NUM_LINES, = 14. Podes cambiar o número de liñas de caché actualizando o rexistro CSR_NUM_LINES.
Táboa 8. Modos de proba
Diagnóstico FPGA: fpgadiag
A utilidade fpgadiag inclúe varias probas para diagnosticar, probar e informar sobre o hardware FPGA. Use a utilidade fpgadiag para executar todos os modos de proba. Para obter máis información sobre o uso da utilidade fpgadiag, consulte a sección fpgadiag na Guía de ferramentas de Open Programable Acceleration Engine (OPAE).
Modo NLB0 Hello_FPGA Fluxo de proba
- O software inicializa a memoria de estado do dispositivo (DSM) a cero.
- O software escribe o enderezo BASE DSM na AFU. CSR Write (DSM_BASE_H), CSRWrite (DSM_BASE_L)
- O software prepara o búfer de memoria de orixe e destino. Esta preparación é específica da proba.
- O software escribe CSR_CTL[2:0]= 0x1. Esta escritura saca a proba do reinicio e pasa ao modo de configuración. A configuración só pode continuar cando CSR_CTL[0]=1 e CSR_CTL[1]=1.
- O software configura os parámetros de proba, como src, destaddress, csr_cfg, num lines, etc.
- CSR de software escribe CSR_CTL[2:0]= 0x3. O AF comeza a execución da proba.
- Finalización da proba:
- O hardware finaliza cando a proba finaliza ou detecta un erro. Ao finalizar, o hardware AF actualiza DSM_STATUS. O software consulta DSM_STATUS[31:0]==1 para detectar a finalización da proba.
- O software pode forzar a finalización da proba escribindo CSR writes CSR_CTL[2:0]=0x7. Actualizacións de hardware AF DSM_STATUS.
Historial de revisións de documentos para a guía de usuario da Unidade Funcional do Acelerador de Loopback Nativo (AFU).
| Versión do documento | Aceleración Intel Versión Stack | Cambios |
| 2019.08.05 | 2.0 (compatible con Intel
Quartus Prime Pro Edition 18.1.2) e 1.2 (compatible con Intel Quartus Prime Pro Edition 17.1.1) |
Engadido soporte para a plataforma Intel FPGA PAC D5005 na versión actual. |
| 2018.12.04 | 1.2 (compatible con Intel
Quartus® Prime Pro Edition 17.1.1) |
Liberación de mantemento. |
| 2018.08.06 | 1.1 (compatible con Intel
Quartus Prime Pro Edition 17.1.1) e 1.0 (compatible con Intel Quartus Prime Pro Edition 17.0.0) |
Actualizouse a localización do código fonte dos NLBample AFU en O NLB Sample Función de aceleración (AF) sección. |
| 2018.04.11 | 1.0 (compatible con Intel
Quartus Prime Pro Edition 17.0.0) |
Lanzamento inicial. |
Intel Corporation. Todos os dereitos reservados. Intel, o logotipo de Intel e outras marcas de Intel son marcas comerciais de Intel Corporation ou das súas subsidiarias. Intel garante o rendemento dos seus produtos FPGA e semicondutores segundo as especificacións actuais de acordo coa garantía estándar de Intel, pero resérvase o dereito de facer cambios en calquera produto e servizo en calquera momento e sen previo aviso. Intel non asume ningunha responsabilidade ou responsabilidade derivada da aplicación ou uso de calquera información, produto ou servizo descrito aquí, salvo que Intel o acorde expresamente por escrito. Recoméndase aos clientes de Intel que obteñan a versión máis recente das especificacións do dispositivo antes de confiar en calquera información publicada e antes de facer pedidos de produtos ou servizos. *Outros nomes e marcas poden ser reclamados como propiedade doutros.
Documentos/Recursos
 |
Unidade funcional do acelerador de loopback nativo de intel (AFU) [pdfGuía do usuario Unidade funcional do acelerador de bucle nativo AFU, Loopback nativo, unidade funcional do acelerador AFU, unidade funcional AFU |