![]() Telemetria no Junos para cargas de trabalho de IA/ML
Telemetria no Junos para cargas de trabalho de IA/ML
Autor: Shalini Mukherjee
Introdução
Como o tráfego do cluster de IA requer redes sem perdas com alto rendimento e baixa latência, um elemento crítico da rede de IA é a coleta de dados de monitoramento. O Junos Telemetry permite o monitoramento granular de indicadores-chave de desempenho, incluindo limites e contadores para gerenciamento de congestionamento e balanceamento de carga de tráfego. As sessões gRPC oferecem suporte ao streaming de dados de telemetria. O gRPC é uma estrutura moderna, de código aberto e de alto desempenho, construída no transporte HTTP/2. Ele capacita recursos de streaming bidirecional nativos e inclui metadados personalizados flexíveis em cabeçalhos de solicitação. A etapa inicial na telemetria é saber quais dados devem ser coletados. Podemos então analisar esses dados em vários formatos. Depois de coletar os dados, é importante apresentá-los em um formato que seja fácil de monitorar, tomar decisões e melhorar o serviço oferecido. Neste artigo, usamos uma pilha de telemetria composta por Telegraf, InfluxDB e Grafana. Essa pilha de telemetria coleta dados usando um modelo push. Os modelos pull tradicionais exigem muitos recursos, exigem intervenção manual e podem incluir lacunas de informação nos dados que coletam. Os modelos push superam essas limitações ao entregar dados de forma assíncrona. Eles enriquecem os dados usando tags e nomes. Uma vez que os dados estão em um formato mais legível, nós os armazenamos em um banco de dados e os utilizamos em uma visualização interativa web aplicativo para analisar a rede. A Figura 1 nos mostra como essa pilha é projetada para coleta, armazenamento e visualização de dados eficientes, desde dispositivos de rede enviando dados para o coletor até os dados sendo exibidos em painéis para análise.

Pilha TIG
Usamos um servidor Ubuntu para instalar todo o software, incluindo a pilha TIG.
Telégrafo
Para coletar dados, usamos o Telegraf em um servidor Ubuntu rodando 22.04.2. A versão do Telegraf rodando nesta demo é 1.28.5.
Telegraf é um agente de servidor controlado por plugin para coletar e reportar métricas. Ele usa processador plugins para enriquecer e normalizar os dados. A saída plugins são usados para enviar esses dados para vários armazenamentos de dados. Neste documento usamos dois plugins: um para sensores openconfig e outro para sensores nativos Juniper.
InfluxoDB
Para armazenar os dados em um banco de dados de séries temporais, usamos o InfluxDB. O plugin de saída no Telegraf envia os dados para o InfluxDB, que os armazena de uma maneira altamente eficiente. Estamos usando a V1.8, pois não há CLI presente para a V2 e acima.
Grafana
O Grafana é usado para visualizar esses dados. O Grafana extrai os dados do InfluxDB e permite que os usuários criem painéis ricos e interativos. Aqui, estamos executando a versão 10.2.2.
Configuração no switch
Para implementar essa pilha, primeiro precisamos configurar o switch conforme mostrado na Figura 2. Usamos a porta 50051. Qualquer porta pode ser usada aqui. Faça login no switch QFX e adicione a seguinte configuração.

Observação: Esta configuração é para laboratórios/POCs, pois a senha é transmitida em texto simples. Use SSL para evitar isso.
Ambiente

Nginx
Isso é necessário se você não conseguir expor a porta na qual o Grafana está hospedado. O próximo passo é instalar o nginx no servidor Ubuntu para servir como um agente de proxy reverso. Depois que o nginx estiver instalado, adicione as linhas mostradas na Figura 4 ao arquivo “default” e mova o arquivo de /etc/nginx para /etc/nginx/sites-enabled.


Certifique-se de que o firewall esteja ajustado para dar acesso total ao serviço nginx, conforme mostrado na Figura 5.

Depois que o nginx estiver instalado e as alterações necessárias forem feitas, poderemos acessar o Grafana a partir de um web navegador usando o endereço IP do servidor Ubuntu onde todo o software está instalado.
Há uma pequena falha no Grafana que não permite redefinir a senha padrão. Use estas etapas se você se deparar com esse problema.
Passos a serem executados no servidor Ubuntu para definir a senha no Grafana:
- Vá para /var/lib/grafana/grafana.db
- Instalar sqllite3
ou sudo apt install sqlite3 - Execute este comando no seu terminal
o sqlite3 grafana.db - O prompt de comando do SQLite é aberto; execute a seguinte consulta:
>excluir do usuário onde login='admin' - Reinicie o grafana e digite admin como nome de usuário e senha. Ele solicita uma nova senha.
Depois que todo o software estiver instalado, crie o arquivo de configuração no Telegraf que ajudará a extrair os dados de telemetria do switch e enviá-los ao InfluxDB.
Plug-in de sensor Openconfig
No servidor Ubuntu, edite o arquivo /etc/telegraf/telegraf.conf para adicionar todos os plugins e sensores. Para os sensores openconfig, usamos o plugin gNMI mostrado na Figura 6. Para fins de demonstração, adicione o nome do host como “spine1”, o número da porta “50051” que é usado para gRPC, o nome de usuário e a senha do switch e o número de segundos para rediscagem em caso de falha.
Na estrofe de assinatura, adicione um nome exclusivo, “cpu” para este sensor em particular, o caminho do sensor e o intervalo de tempo para pegar esses dados do switch. Adicione o mesmo plugin inputs.gnmi e inputs.gnmi.subscription para todos os sensores de configuração aberta. (Figura 6)

Plug-in de sensor nativo
Este é um plugin de interface de telemetria Juniper usado para sensores nativos. No mesmo arquivo telegraf.conf, adicione o plugin de sensor nativo inputs.jti_openconfig_telemetry onde os campos são quase os mesmos que openconfig. Use um ID de cliente exclusivo para cada sensor; aqui, usamos “telegraf3”. O nome exclusivo usado aqui para este sensor é “mem” (Figura 7).

Por fim, adicione um plugin de saída outputs.influxdb para enviar esses dados do sensor para o InfluxDB. Aqui, o banco de dados é chamado de “telegraf” com nome de usuário como “influx” e senha “influxdb” (Figura 8).

Depois de editar o arquivo telegraf.conf, reinicie o serviço telegraf. Agora, verifique no InfluxDB CLI para certificar-se de que as medições foram criadas para todos os sensores exclusivos. Digite “influx” para entrar no InfluxDB CLI.

Conforme visto na Figura 9, entre no prompt do influxDB e use o banco de dados “telegraf”. Todos os nomes exclusivos dados aos sensores são listados como medições.
Para ver a saída de qualquer medição, apenas para ter certeza de que o arquivo telegraf está correto e o sensor está funcionando, use o comando “select * from cpu limit 1” conforme mostrado na Figura 10.

Toda vez que forem feitas alterações no arquivo telegraf.conf, certifique-se de parar o InfluxDB, reiniciar o Telegraf e, em seguida, iniciar o InfluxDB.
Faça login no Grafana pelo navegador e crie painéis depois de garantir que os dados estão sendo coletados corretamente.
Vá para Conexões > InfuxDB > Adicionar nova fonte de dados.

- Dê um nome a esta fonte de dados. Nesta demonstração, é “test-1”.
- Na estrofe HTTP, use o IP do servidor Ubuntu e a porta 8086.

- Nos detalhes do InfluxDB, use o mesmo nome de banco de dados, “telegraf”, e forneça o nome de usuário e a senha do servidor Ubuntu.
- Clique em Salvar e testar. Certifique-se de ver a mensagem “sucesso”.

- Depois que a fonte de dados for adicionada com sucesso, vá para Dashboards e clique em New. Vamos criar alguns dashboards que são essenciais para cargas de trabalho de IA/ML no modo editor.
Examparquivos de gráficos de sensores
Os seguintes são examparquivos de alguns contadores importantes que são essenciais para monitorar uma rede de IA/ML.
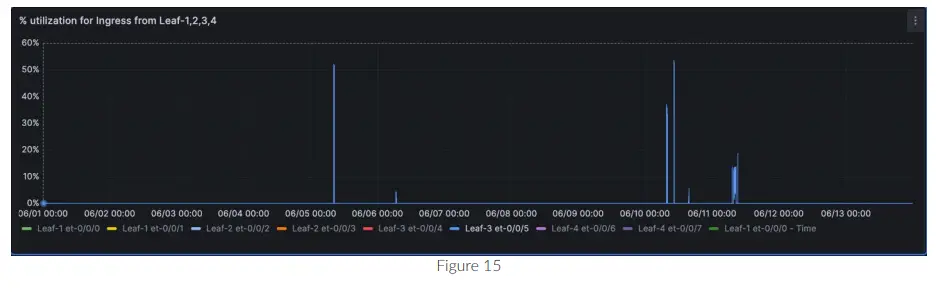
Percentualtage utilização para uma interface de entrada et-0/0/0 na espinha-1

- Selecione a fonte de dados como teste-1.
- Na seção FROM, selecione a medição como “interface”. Este é o nome exclusivo usado para este caminho do sensor.
- Na seção ONDE, selecione dispositivo::tag, e no tag valor, selecione o nome do host do switch, ou seja, spine1.
- Na seção SELECT, escolha o ramo do sensor que você deseja monitorar; neste caso, escolha “field(/interfaces/interface[if_name='et-0/0/0']/state/counters/if_in_1s_octets)”. Agora, na mesma seção, clique em “+” e adicione este cálculo matemático (/50000000000 * 100). Estamos basicamente calculando a porcentagemtage utilização de uma interface 400G.
- Certifique-se de que o FORMATO seja “série temporal” e nomeie o gráfico na seção ALIAS.
 Ocupação máxima do buffer para qualquer fila
Ocupação máxima do buffer para qualquer fila

- Selecione a fonte de dados como teste-1.
- Na seção FROM, selecione a medição como “buffer”.
- Na seção WHERE, há três campos para preencher. Selecione o dispositivo::tag, e no tag valor selecione o nome do host do switch (por exemplo, spine-1); E selecione /cos/interfaces/interface/@name::tag e selecione a interface (ou seja, et- 0/0/0); E selecione a fila também, /cos/interfaces/interface/queues/queue/@queue::tag e escolha o número da fila 4.
- Na seção SELECT, escolha o branch do sensor que você deseja monitorar; neste caso, escolha “field(/cos/interfaces/interface/queues/queue/PeakBufferOccupancy)”.
- Certifique-se de que o FORMATO seja “série temporal” e nomeie o gráfico na seção ALIAS.
Você pode reunir dados de várias interfaces no mesmo gráfico, como visto na Figura 17 para et-0/0/0, et-0/0/1, et-0/0/2 etc.

PFC e ECN significam derivada

Para encontrar a derivada média (a diferença de valor dentro de um intervalo de tempo), use o modo de consulta bruta.
Esta é a consulta de influxo que usamos para encontrar a derivada média entre dois valores de PFC em et-0/0/0 de Spine-1 em um segundo.
SELECIONE derivado(mean(“/interfaces/interface[if_name='et-0/0/0′]/state/pfc-counter/tx_pkts”), 1s) DE “interface” ONDE (“dispositivo”::tag = 'Spine-1') AND $timeFilter GROUP BY time($interval)

SELECIONE derivado(mean(“/interfaces/interface[if_name='et-0/0/8′]/state/error-counters/ecn_ce_marked_pkts”), 1s) DE “interface” ONDE (“dispositivo”::tag = 'Spine-1') AND $timeFilter GROUP BY time($interval)

Erros de recursos de entrada significam derivada

A derivada média da consulta bruta para erros de recursos é:
SELECIONE derivado(mean(“/interfaces/interface[if_name='et-0/0/0′]/state/error-counters/if_in_resource_errors”), 1s) DE “interface” ONDE (“dispositivo”::tag = 'Spine-1') AND $timeFilter GROUP BY time($interval)

Quedas na cauda significam derivada

A consulta bruta para a derivada média das quedas de cauda é:
SELECIONE derivado(média(“/cos/interfaces/interface/filas/fila/tailDropBytes”), 1s) DE “buffer” ONDE (“dispositivo”::tag = 'Folha-1' AND “/cos/interfaces/interface/@nome”::tag = 'et-0/0/0' AND “/cos/interfaces/interface/queues/queue/@queue”::tag = '4') E $timeFilter GRUPO POR time($__interval) preenchimento(nulo)
Utilização da CPU

- Selecione a fonte de dados como teste-1.
- Na seção FROM, selecione a medição como “newcpu”
- No WHERE, há três campos para preencher. Selecione o dispositivo::tag e no tag valor selecione o nome do host do switch (por exemplo, spine-1). E em /components/component/properties/property/name:tage selecione cpuutilization-total AND em nome::tag selecione RE0.
- Na seção SELECT, escolha o branch do sensor que você quer monitorar. Neste caso, escolha “field(state/value)”.

A consulta bruta para encontrar a derivada não negativa de quedas de cauda para vários switches em várias interfaces em bits/s.
SELECIONE non_negative_derivative(mean(“/cos/interfaces/interface/queues/queue/tailDropBytes”), 1s)*8 DE “buffer” ONDE (dispositivo::tag =~ /^Spine-[1-2]$/) e (“/cos/interfaces/interface/@nome”::tag =~ /et-0\/0\/[0-9]/ ou “/cos/interfaces/interface/@nome”::tag=~/et-0\/0\/1[0-5]/) E $timeFilter GRUPO POR time($__interval),device::tag preencher(nulo)

Estas foram algumas das examparquivos dos gráficos que podem ser criados para monitorar uma rede AI/ML.
Resumo
Este artigo ilustra o método de extração de dados de telemetria e sua visualização por meio da criação de gráficos. Este artigo fala especificamente sobre sensores de IA/ML, nativos e openconfig, mas a configuração pode ser usada para todos os tipos de sensores. Também incluímos soluções para vários problemas que você pode enfrentar ao criar a configuração. As etapas e saídas descritas neste artigo são específicas para as versões da pilha TIG mencionadas anteriormente. Elas estão sujeitas a alterações dependendo da versão do software, dos sensores e da versão do Junos.
Referências
Juniper Yang Data Model Explorer para todas as opções de sensores
https://apps.juniper.net/ydm-explorer/
Fórum Openconfig para sensores Openconfig
https://www.openconfig.net/projects/models/
![]()
Sede Corporativa e de Vendas
Português Juniper Networks, Inc.
1133 Maneira da Inovação
Sunnyvale, CA 94089 EUA
Telefone: 888. JUNIPER (888.586.4737)
ou +1.408.745.2000
Fax: +1.408.745.2100
www.juniper.net
Sede da APAC e EMEA
Juniper Networks International BV
Avenida Boeing 240
1119 PZ Schiphol-Rijk
Amsterdã, Holanda
Telefone: +31.207.125.700
Fax: +31.207.125.701
Copyright 2023 Juniper Networks. Inc. Todos os direitos reservados. Juniper Networks, o logotipo da Juniper Networks, Juniper, Junos e outras marcas comerciais são marcas registradas da Juniper Networks. inc. e/ou suas afiliadas nos Estados Unidos e em outros países. Outros nomes podem ser marcas comerciais de seus respectivos proprietários. A Juniper Networks não assume nenhuma responsabilidade por quaisquer imprecisões neste documento. A Juniper Networks reserva-se o direito de alterar, modificar, transferir ou revisar esta publicação sem aviso prévio.
Envie feedback para: design-center-comments@juniper.net V1.0/240807/ejm5-telemetria-junos-ai-ml
Documentos / Recursos
 |
Telemetria Juniper NETWORKS em Junos para software de cargas de trabalho AI ML [pdf] Guia do Usuário Telemetria em Junos para software de cargas de trabalho de AI ML, Junos para software de cargas de trabalho de AI ML, software de cargas de trabalho de AI ML, software de cargas de trabalho, software |