![]() Telemetria in Junos per carichi di lavoro AI/ML
Telemetria in Junos per carichi di lavoro AI/ML
Autore: Shalini Mukherjee
Introduzione
Poiché il traffico del cluster AI richiede reti lossless con elevata produttività e bassa latenza, un elemento critico della rete AI è la raccolta di dati di monitoraggio. Junos Telemetry consente il monitoraggio granulare degli indicatori chiave delle prestazioni, tra cui soglie e contatori per la gestione della congestione e il bilanciamento del carico del traffico. Le sessioni gRPC supportano lo streaming di dati di telemetria. gRPC è un framework moderno, open source e ad alte prestazioni basato sul trasporto HTTP/2. Abilita le capacità di streaming bidirezionale nativo e include metadati personalizzati flessibili nelle intestazioni delle richieste. Il passaggio iniziale nella telemetria è sapere quali dati devono essere raccolti. Possiamo quindi analizzare questi dati in vari formati. Una volta raccolti i dati, è importante presentarli in un formato che sia facile da monitorare, prendere decisioni e migliorare il servizio offerto. In questo documento, utilizziamo uno stack di telemetria composto da Telegraf, InfluxDB e Grafana. Questo stack di telemetria raccoglie i dati utilizzando un modello push. I modelli pull tradizionali sono intensivi in termini di risorse, richiedono un intervento manuale e potrebbero includere lacune informative nei dati che raccolgono. I modelli push superano queste limitazioni fornendo dati in modo asincrono. Arricchiscono i dati utilizzando tags e nomi. Una volta che i dati sono in un formato più leggibile, li archiviamo in un database e li utilizziamo in una visualizzazione interattiva web applicazione per l'analisi della rete. La figura 1 ci mostra come questo stack è progettato per una raccolta, archiviazione e visualizzazione efficienti dei dati, dai dispositivi di rete che inviano i dati al collettore ai dati visualizzati sui dashboard per l'analisi.

Pila TIG
Abbiamo utilizzato un server Ubuntu per installare tutto il software incluso lo stack TIG.
Telegrafo
Per raccogliere i dati, utilizziamo Telegraf su un server Ubuntu con versione 22.04.2. La versione di Telegraf in esecuzione in questa demo è 1.28.5.
Telegraf è un agente server basato su plugin per la raccolta e la segnalazione di metriche. Utilizza il processore plugins arricchire e normalizzare i dati. L'uscita plugins vengono utilizzati per inviare questi dati a vari archivi dati. In questo documento ne usiamo due plugins: uno per i sensori OpenConfig e l'altro per i sensori nativi Juniper.
InfluxDB
Per memorizzare i dati in un database di serie temporali, utilizziamo InfluxDB. Il plugin di output in Telegraf invia i dati a InfluxDB, che li memorizza in modo altamente efficiente. Stiamo utilizzando V1.8 poiché non è presente alcuna CLI per V2 e versioni successive.
Grafana
Grafana viene utilizzato per visualizzare questi dati. Grafana estrae i dati da InfluxDB e consente agli utenti di creare dashboard ricche e interattive. Qui, stiamo eseguendo la versione 10.2.2.
Configurazione sullo switch
Per implementare questo stack, dobbiamo prima configurare lo switch come mostrato nella Figura 2. Abbiamo utilizzato la porta 50051. Qui può essere utilizzata qualsiasi porta. Accedi allo switch QFX e aggiungi la seguente configurazione.

Nota: Questa configurazione è per laboratori/POC poiché la password viene trasmessa in chiaro. Utilizzare SSL per evitarlo.
Ambiente

Nginx
Ciò è necessario se non si riesce a esporre la porta su cui è ospitato Grafana. Il passo successivo è installare nginx sul server Ubuntu per fungere da agente proxy inverso. Una volta installato nginx, aggiungere le righe mostrate nella Figura 4 al file "default" e spostare il file da /etc/nginx a /etc/nginx/sites-enabled.


Assicurarsi che il firewall sia regolato per garantire l'accesso completo al servizio nginx come mostrato nella Figura 5.

Una volta installato nginx e apportate le modifiche richieste, dovremmo essere in grado di accedere a Grafana da a web browser utilizzando l'indirizzo IP del server Ubuntu su cui è installato tutto il software.
C'è un piccolo problema tecnico in Grafana che non ti consente di reimpostare la password predefinita. Utilizza questi passaggi se riscontri questo problema.
Passaggi da eseguire sul server Ubuntu per impostare la password in Grafana:
- Vai a /var/lib/grafana/grafana.db
- Installa sqllite3
o sudo apt install sqlite3 - Esegui questo comando sul tuo terminale
o sqlite3 grafana.db - Si apre il prompt dei comandi di SQLite; eseguire la seguente query:
>elimina dall'utente dove login='admin' - Riavvia grafana e digita admin come username e password. Ti chiederà una nuova password.
Una volta installato tutto il software, crea il file di configurazione in Telegraf che ti aiuterà a estrarre i dati di telemetria dallo switch e a inviarli a InfluxDB.
Plug-in sensore Openconfig
Sul server Ubuntu, modifica il file /etc/telegraf/telegraf.conf per aggiungere tutti i dati richiesti plugins e sensori. Per i sensori openconfig, utilizziamo il plugin gNMI mostrato nella Figura 6. A scopo dimostrativo, aggiungiamo il nome host come "spine1", il numero di porta "50051" che viene utilizzato per gRPC, il nome utente e la password dello switch e il numero di secondi per la ricomposizione in caso di errore.
Nella stanza di sottoscrizione, aggiungi un nome univoco, "cpu" per questo particolare sensore, il percorso del sensore e l'intervallo di tempo per acquisire questi dati dallo switch. Aggiungi lo stesso plugin inputs.gnmi e inputs.gnmi.subscription per tutti i sensori open config. (Figura 6)

Plugin del sensore nativo
Questo è un plugin di interfaccia di telemetria Juniper utilizzato per sensori nativi. Nello stesso file telegraf.conf, aggiungi il plugin del sensore nativo inputs.jti_openconfig_telemetry dove i campi sono quasi gli stessi di openconfig. Utilizza un ID client univoco per ogni sensore; qui, utilizziamo "telegraf3". Il nome univoco utilizzato qui per questo sensore è "mem" (Figura 7).

Infine, aggiungi un plugin di output outputs.influxdb per inviare questi dati del sensore a InfluxDB. Qui, il database è denominato "telegraf" con username "influx" e password "influxdb" (Figura 8).

Una volta modificato il file telegraf.conf, riavvia il servizio telegraf. Ora, controlla nella CLI InfluxDB per assicurarti che le misurazioni siano state create per tutti i sensori univoci. Digita "influx" per entrare nella CLI InfluxDB.

Come si vede nella Figura 9, immettere il prompt influxDB e utilizzare il database “telegraf”. Tutti i nomi univoci assegnati ai sensori sono elencati come misurazioni.
Per visualizzare l'output di una qualsiasi misurazione, solo per assicurarsi che il file telegraf sia corretto e che il sensore funzioni, utilizzare il comando "select * from cpu limit 1" come mostrato nella Figura 10.

Ogni volta che vengono apportate modifiche al file telegraf.conf, assicurarsi di arrestare InfluxDB, riavviare Telegraf e quindi avviare InfluxDB.
Accedere a Grafana dal browser e creare dashboard dopo essersi assicurati che i dati vengano raccolti correttamente.
Vai su Connessioni > InfuxDB > Aggiungi nuova origine dati.

- Assegna un nome a questa fonte dati. In questa demo è “test-1”.
- Nella sezione HTTP, utilizzare l'IP del server Ubuntu e la porta 8086.

- Nei dettagli di InfluxDB, utilizzare lo stesso nome del database, "telegraf", e fornire il nome utente e la password del server Ubuntu.
- Fai clic su Salva e prova. Assicurati di vedere il messaggio "riuscito".

- Una volta aggiunta correttamente la fonte dati, vai su Dashboard e clicca su New. Creiamo alcune dashboard essenziali per i carichi di lavoro AI/ML in modalità editor.
Exampfile di grafici dei sensori
Di seguito sono riportati esempiampfile di alcuni importanti contatori essenziali per il monitoraggio di una rete AI/ML.
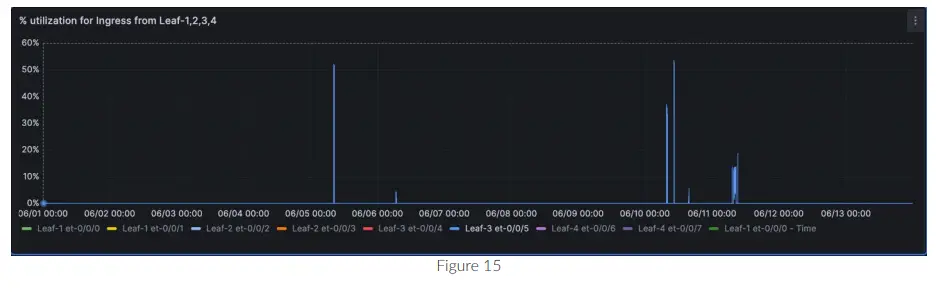
percentualetage utilizzo per un'interfaccia di ingresso et-0/0/0 su spine-1

- Selezionare la fonte dati come test-1.
- Nella sezione FROM, seleziona la misurazione come “interfaccia”. Questo è il nome univoco utilizzato per questo percorso del sensore.
- Nella sezione DOVE, seleziona dispositivo::tag, e nel tag valore, seleziona il nome host dello switch, ovvero spine1.
- Nella sezione SELECT, scegli il ramo del sensore che vuoi monitorare; in questo caso scegli “field(/interfaces/interface[if_name='et-0/0/0']/state/counters/if_in_1s_octets)”. Ora nella stessa sezione, clicca su “+” e aggiungi questo calcolo matematico (/50000000000 * 100). Stiamo fondamentalmente calcolando la percentage utilizzo di un'interfaccia 400G.
- Assicurati che il FORMATO sia "serie temporale" e assegna un nome al grafico nella sezione ALIAS.
 Occupazione massima del buffer per qualsiasi coda
Occupazione massima del buffer per qualsiasi coda

- Selezionare la fonte dati come test-1.
- Nella sezione FROM, seleziona la misurazione come “buffer”.
- Nella sezione WHERE, ci sono tre campi da compilare. Seleziona dispositivo::tag, e nel tag valore seleziona il nome host dello switch (ad esempio spine-1); E seleziona /cos/interfaces/interface/@name::tag e seleziona l'interfaccia (ad esempio et- 0/0/0); E seleziona anche la coda, /cos/interfaces/interface/queues/queue/@queue::tag e scegli la coda numero 4.
- Nella sezione SELECT, seleziona il ramo del sensore che vuoi monitorare; in questo caso seleziona “field(/cos/interfaces/interface/queues/queue/PeakBufferOccupancy).”
- Assicurati che il FORMATO sia "serie temporale" e assegna un nome al grafico nella sezione ALIAS.
È possibile confrontare i dati di più interfacce sullo stesso grafico, come mostrato nella Figura 17 per et-0/0/0, et-0/0/1, et-0/0/2 ecc.

PFC e ECN significano derivati

Per trovare la derivata media (la differenza di valore in un intervallo di tempo), utilizzare la modalità di query raw.
Questa è la query di afflusso che abbiamo utilizzato per trovare la derivata media tra due valori PFC su et-0/0/0 di Spine-1 in un secondo.
SELECT derivative(mean(“/interfaces/interface[if_name='et-0/0/0′]/state/pfc-counter/tx_pkts”), 1s) FROM “interface” WHERE (“device”::tag = 'Spine-1') E $timeFilter GRUPPO PER ora($intervallo)

SELECT derivative(mean(“/interfaces/interface[if_name='et-0/0/8′]/state/error-counters/ecn_ce_marked_pkts”), 1s) FROM “interface” WHERE (“device”::tag = 'Spine-1') E $timeFilter GRUPPO PER ora($intervallo)

Gli errori delle risorse di input significano derivati

La query grezza per gli errori di risorse significa che la derivata media è:
SELECT derivative(mean(“/interfaces/interface[if_name='et-0/0/0′]/state/error-counters/if_in_resource_errors”), 1s) FROM “interface” WHERE (“device”::tag = 'Spine-1') E $timeFilter GRUPPO PER ora($intervallo)

Le gocce di coda significano derivato

La query grezza per la derivata media delle cadute di coda è:
SELECT derivative(mean(“/cos/interfaces/interface/queues/queue/tailDropBytes”), 1s) FROM “buffer” WHERE (“device”::tag = 'Foglia-1' AND “/cos/interfaces/interfaccia/@nome”::tag = 'et-0/0/0' AND “/cos/interfaces/interface/queues/queue/@queue”::tag = '4') E $timeFilter GRUPPO PER time($__interval) fill(null)
Utilizzo della CPU

- Selezionare la fonte dati come test-1.
- Nella sezione FROM, seleziona la misurazione come “newcpu”
- Nel WHERE, ci sono tre campi da compilare. Seleziona dispositivo::tag e nel tag valore seleziona il nome host dello switch (ad esempio spine-1). E in /components/component/properties/property/name:tage seleziona cpuutilization-total AND nel nome::tag selezionare RE0.
- Nella sezione SELECT, scegli il ramo del sensore che vuoi monitorare. In questo caso, scegli “field(state/value)”.

Query grezza per trovare la derivata non negativa dei tail drop per più switch su più interfacce in bit/sec.
SELEZIONA non_negative_derivative(mean(“/cos/interfacce/interfaccia/code/coda/tailDropBytes”), 1s)*8 DA “buffer” DOVE (dispositivo::tag =~ /^Spine-[1-2]$/) e (“/cos/interfaces/interfaccia/@nome”::tag =~ /et-0\/0\/[0-9]/ o “/cos/interfaces/interface/@name”::tag=~/et-0\/0\/1[0-5]/) E $timeFilter RAGGRUPPAMENTO PER time($__interval),device::tag riempimento(null)

Questi erano alcuni degli example dei grafici che possono essere creati per il monitoraggio di una rete AI/ML.
Riepilogo
Questo documento illustra il metodo per estrarre i dati di telemetria e visualizzarli tramite la creazione di grafici. Questo documento parla specificamente di sensori AI/ML, sia nativi che openconfig, ma la configurazione può essere utilizzata per tutti i tipi di sensori. Abbiamo anche incluso soluzioni per molteplici problemi che potresti incontrare durante la creazione della configurazione. I passaggi e gli output illustrati in questo documento sono specifici per le versioni dello stack TIG menzionate in precedenza. Sono soggetti a modifiche a seconda della versione del software, dei sensori e della versione Junos.
Riferimenti
Juniper Yang Data Model Explorer per tutte le opzioni dei sensori
https://apps.juniper.net/ydm-explorer/
Forum Openconfig per sensori Openconfig
https://www.openconfig.net/projects/models/
![]()
Sede aziendale e commerciale
Società per azioni Juniper Networks, Inc.
1133 Innovazione Way
Sunnyvale, CA 94089 Stati Uniti
Telefono: 888. JUNIPER (888.586.4737)
o +1.408.745.2000
Fax: +1.408.745.2100
www.juniper.net
Sede APAC ed EMEA
Juniper Networks International BV
Viale Boeing 240
1119 PZ Schiphol-Rijk
Amsterdam, Paesi Bassi
Telefono: +31.207.125.700
Fax: +31.207.125.701
Copyright 2023 Juniper Networks. Inc. Tutti i diritti riservati. Juniper Networks, il logo Juniper Networks, Juniper, Junos e altri marchi sono marchi registrati di Juniper Networks. inc. e/o delle sue affiliate negli Stati Uniti e in altri paesi. Altri nomi possono essere marchi dei rispettivi proprietari. Juniper Networks non si assume alcuna responsabilità per eventuali inesattezze presenti nel presente documento. Juniper Networks si riserva il diritto di modificare, modificare, trasferire o altrimenti rivedere questa pubblicazione senza preavviso.
Invia feedback a: design-center-comments@juniper.net V1.0/240807/ejm5-telemetria-junos-ai-ml
Documenti / Risorse
 |
Telemetria Juniper NETWORKS nel software Junos per carichi di lavoro AI ML [pdf] Guida utente Telemetria nel software Junos per carichi di lavoro AI ML, Software Junos per carichi di lavoro AI ML, Software per carichi di lavoro AI ML, Software per carichi di lavoro, Software |