![]() Telemetry នៅក្នុង Junos សម្រាប់បន្ទុកការងារ AI/ML
Telemetry នៅក្នុង Junos សម្រាប់បន្ទុកការងារ AI/ML
អ្នកនិពន្ធ៖ Shalini Mukherjee
សេចក្តីផ្តើម
ដោយសារ AI cluster traffic ទាមទារបណ្តាញដែលបាត់បង់ជាមួយនឹងការបញ្ជូនខ្ពស់ និង latency ទាប ធាតុសំខាន់នៃបណ្តាញ AI គឺការប្រមូលទិន្នន័យត្រួតពិនិត្យ។ Junos Telemetry អនុញ្ញាតឱ្យមានការត្រួតពិនិត្យយ៉ាងម៉ត់ចត់នៃសូចនាករដំណើរការសំខាន់ៗ រួមទាំងកម្រិតចាប់ផ្ដើម និងបញ្ជរសម្រាប់ការគ្រប់គ្រងការកកស្ទះ និងតុល្យភាពបន្ទុក។ វគ្គ gRPC គាំទ្រការផ្សាយទិន្នន័យ telemetry ។ gRPC គឺជាប្រព័ន្ធបើកចំហទំនើប និងមានដំណើរការខ្ពស់ដែលត្រូវបានបង្កើតឡើងលើការដឹកជញ្ជូន HTTP/2។ វាផ្តល់អំណាចដល់សមត្ថភាពស្ទ្រីមទ្វេទិសដើម និងរួមបញ្ចូលទិន្នន័យមេតាផ្ទាល់ខ្លួនដែលអាចបត់បែនបាននៅក្នុងបឋមកថាសំណើ។ ជំហានដំបូងក្នុង telemetry គឺត្រូវដឹងពីទិន្នន័យដែលត្រូវប្រមូល។ បន្ទាប់មកយើងអាចវិភាគទិន្នន័យនេះក្នុងទម្រង់ផ្សេងៗ។ នៅពេលដែលយើងប្រមូលទិន្នន័យ វាមានសារៈសំខាន់ណាស់ក្នុងការបង្ហាញវាជាទម្រង់ដែលងាយស្រួលក្នុងការត្រួតពិនិត្យ ធ្វើការសម្រេចចិត្ត និងកែលម្អសេវាកម្មដែលកំពុងត្រូវបានផ្តល់ជូន។ នៅក្នុងក្រដាសនេះ យើងប្រើជង់ telemetry ដែលរួមមាន Telegraf, InfluxDB និង Grafana។ ជង់ telemetry នេះប្រមូលទិន្នន័យដោយប្រើគំរូរុញ។ គំរូទាញបែបប្រពៃណីគឺពឹងផ្អែកខ្លាំងលើធនធាន ទាមទារការអន្តរាគមន៍ដោយដៃ ហើយអាចរួមបញ្ចូលនូវគម្លាតព័ត៌មាននៅក្នុងទិន្នន័យដែលពួកគេប្រមូលបាន។ ម៉ូដែល Push យកឈ្នះលើដែនកំណត់ទាំងនេះដោយការបញ្ជូនទិន្នន័យដោយមិនសមកាលកម្ម។ ពួកគេបង្កើនទិន្នន័យដោយប្រើប្រាស់ងាយស្រួលប្រើ tags និងឈ្មោះ។ នៅពេលដែលទិន្នន័យស្ថិតនៅក្នុងទម្រង់ដែលអាចអានបានកាន់តែច្រើន យើងរក្សាទុកវាក្នុងមូលដ្ឋានទិន្នន័យ ហើយប្រើវាក្នុងរូបភាពអន្តរកម្ម web កម្មវិធីសម្រាប់ការវិភាគបណ្តាញ។ រូប។ 1 បង្ហាញយើងពីរបៀបដែលជង់នេះត្រូវបានរចនាឡើងសម្រាប់ការប្រមូលទិន្នន័យ ការផ្ទុក និងការមើលឃើញប្រកបដោយប្រសិទ្ធភាព ពីឧបករណ៍បណ្តាញដែលរុញទិន្នន័យទៅកាន់អ្នកប្រមូលរហូតដល់ទិន្នន័យដែលត្រូវបានបង្ហាញនៅលើផ្ទាំងគ្រប់គ្រងសម្រាប់ការវិភាគ។

ជង់ TIG
យើងបានប្រើម៉ាស៊ីនមេ Ubuntu ដើម្បីដំឡើងកម្មវិធីទាំងអស់រួមទាំង TIG stack ។
តេឡេក្រាហ្វ
ដើម្បីប្រមូលទិន្នន័យ យើងប្រើ Telegraf នៅលើម៉ាស៊ីនមេ Ubuntu ដែលដំណើរការ 22.04.2។ កំណែ Telegraf ដែលដំណើរការក្នុងការបង្ហាញនេះគឺ 1.28.5។
Telegraf គឺជាភ្នាក់ងារម៉ាស៊ីនមេដែលជំរុញដោយកម្មវិធីជំនួយសម្រាប់ការប្រមូល និងរាយការណ៍ម៉ែត្រ។ វាប្រើខួរក្បាល plugins ដើម្បីបង្កើន និងធ្វើឱ្យទិន្នន័យមានលក្ខណៈធម្មតា។ ទិន្នផល plugins ត្រូវបានប្រើដើម្បីផ្ញើទិន្នន័យនេះទៅកាន់កន្លែងផ្ទុកទិន្នន័យផ្សេងៗ។ នៅក្នុងឯកសារនេះយើងប្រើពីរ plugins៖ មួយសម្រាប់ឧបករណ៍ចាប់សញ្ញា openconfig និងមួយទៀតសម្រាប់ឧបករណ៍ចាប់សញ្ញាដើម Juniper ។
InfluxDB
ដើម្បីរក្សាទុកទិន្នន័យនៅក្នុងមូលដ្ឋានទិន្នន័យស៊េរីពេលវេលា យើងប្រើ InuxDB ។ កម្មវិធីជំនួយលទ្ធផលនៅក្នុង Telegraf បញ្ជូនទិន្នន័យទៅ InuxDB ដែលរក្សាទុកវាតាមរបៀបដែលមានប្រសិទ្ធភាពខ្ពស់។ យើងកំពុងប្រើ V1.8 ព្រោះមិនមាន CLI មានវត្តមានសម្រាប់ V2 និងខ្ពស់ជាងនេះ។
ហ្គ្រាហ្វាណា
Grafana ត្រូវបានប្រើដើម្បីមើលឃើញទិន្នន័យនេះ។ Grafana ទាញទិន្នន័យពី InfluxDB ហើយអនុញ្ញាតឱ្យអ្នកប្រើប្រាស់បង្កើតផ្ទាំងគ្រប់គ្រងដែលសំបូរបែប និងអន្តរកម្ម។ នៅទីនេះយើងកំពុងដំណើរការកំណែ 10.2.2 ។
ការកំណត់រចនាសម្ព័ន្ធនៅលើកុងតាក់
ដើម្បីអនុវត្តជង់នេះ ដំបូងយើងត្រូវកំណត់កុងតាក់ដូចបង្ហាញក្នុងរូបភាពទី 2។ យើងបានប្រើច្រក 50051។ ច្រកណាមួយអាចត្រូវបានប្រើនៅទីនេះ។ ចូលទៅកុងតាក់ QFX ហើយបន្ថែមការកំណត់ដូចខាងក្រោម។

ចំណាំ៖ ការកំណត់នេះគឺសម្រាប់មន្ទីរពិសោធន៍/POCs ដោយសារពាក្យសម្ងាត់ត្រូវបានបញ្ជូនជាអត្ថបទច្បាស់លាស់។ ប្រើ SSL ដើម្បីជៀសវាងបញ្ហានេះ។
បរិស្ថាន

Nginx
វាចាំបាច់ប្រសិនបើអ្នកមិនអាចបង្ហាញច្រកដែល Grafana ត្រូវបានបង្ហោះ។ ជំហានបន្ទាប់គឺត្រូវដំឡើង nginx នៅលើម៉ាស៊ីនមេ Ubuntu ដើម្បីបម្រើជាភ្នាក់ងារប្រូកស៊ីបញ្ច្រាស។ នៅពេលដំឡើង nginx បន្ថែមបន្ទាត់ដែលបង្ហាញក្នុងរូបភាពទី 4 ទៅឯកសារ "លំនាំដើម" ហើយផ្លាស់ទីឯកសារពី /etc/nginx ទៅ /etc/nginx/sites-enabled ។


ត្រូវប្រាកដថាជញ្ជាំងភ្លើងត្រូវបានកែតម្រូវដើម្បីផ្តល់សិទ្ធិចូលដំណើរការពេញលេញទៅកាន់សេវា nginx ដូចបង្ហាញក្នុងរូបភាពទី 5 ។

នៅពេលដែល nginx ត្រូវបានដំឡើង ហើយការផ្លាស់ប្តូរដែលត្រូវការត្រូវបានធ្វើឡើង យើងគួរតែអាចចូលប្រើ Grafana ពី a web កម្មវិធីរុករកតាមអ៊ីនធឺណិតដោយប្រើអាសយដ្ឋាន IP របស់ម៉ាស៊ីនមេ Ubuntu ដែលកម្មវិធីទាំងអស់ត្រូវបានដំឡើង។
មានកំហុសតូចមួយនៅក្នុង Grafana ដែលមិនអនុញ្ញាតឱ្យអ្នកកំណត់ពាក្យសម្ងាត់លំនាំដើមឡើងវិញ។ ប្រើជំហានទាំងនេះ ប្រសិនបើអ្នកជួបប្រទះបញ្ហានេះ។
ជំហានដែលត្រូវអនុវត្តនៅលើម៉ាស៊ីនមេ Ubuntu ដើម្បីកំណត់ពាក្យសម្ងាត់នៅក្នុង Grafana៖
- ចូលទៅកាន់ /var/lib/grafana/grafana.db
- ដំឡើង sqllite3
o sudo apt ដំឡើង sqlite3 - ដំណើរការពាក្យបញ្ជានេះនៅលើស្ថានីយរបស់អ្នក។
o sqlite3 grafana.db - ប្រអប់បញ្ចូលពាក្យបញ្ជា Sqlite បើក; ដំណើរការសំណួរខាងក្រោម៖
> លុបចេញពីអ្នកប្រើប្រាស់ដែលចូល = 'admin' - ចាប់ផ្តើម grafana ឡើងវិញ ហើយវាយ admin ជា username និង password។ វាសួររកពាក្យសម្ងាត់ថ្មី។
នៅពេលដែលកម្មវិធីទាំងអស់ត្រូវបានដំឡើងរួចហើយ សូមបង្កើតឯកសារកំណត់រចនាសម្ព័ន្ធនៅក្នុង Telegraf ដែលនឹងជួយទាញទិន្នន័យតេឡេម៉ែត្រពីកុងតាក់ ហើយរុញវាទៅ InuxDB ។
កម្មវិធីជំនួយឧបករណ៍ចាប់សញ្ញា Openconfig
នៅលើម៉ាស៊ីនមេអ៊ូប៊ុនទូ កែសម្រួលឯកសារ /etc/telegraf/telegraf.conf ដើម្បីបន្ថែមតម្រូវការទាំងអស់ plugins និងឧបករណ៍ចាប់សញ្ញា។ សម្រាប់ឧបករណ៍ចាប់សញ្ញា openconfg យើងប្រើកម្មវិធីជំនួយ gNMI ដែលបង្ហាញក្នុងរូបភាពទី 6។ សម្រាប់គោលបំណងសាកល្បង សូមបន្ថែមឈ្មោះម៉ាស៊ីនជា “spine1” លេខច្រក “50051” ដែលប្រើសម្រាប់ gRPC ឈ្មោះអ្នកប្រើប្រាស់ និងពាក្យសម្ងាត់របស់កុងតាក់ និងលេខ នៃវិនាទីសម្រាប់ការហៅម្តងទៀតក្នុងករណីបរាជ័យ។
នៅក្នុងឃ្លានៃការជាវ សូមបន្ថែមឈ្មោះតែមួយគត់ "cpu" សម្រាប់ឧបករណ៍ចាប់សញ្ញាជាក់លាក់នេះ ផ្លូវរបស់ឧបករណ៍ចាប់សញ្ញា និងចន្លោះពេលសម្រាប់ការចាប់យកទិន្នន័យនេះពីកុងតាក់។ បន្ថែមកម្មវិធីជំនួយដូចគ្នា inputs.gnmi និង inputs.gnmi.subscription សម្រាប់ឧបករណ៍ចាប់សញ្ញា config បើកទាំងអស់។ (រូបភាពទី 6)

កម្មវិធីជំនួយឧបករណ៍ចាប់សញ្ញាដើម
នេះគឺជាកម្មវិធីជំនួយចំណុចប្រទាក់តេឡេម៉ែត្រ Juniper ដែលប្រើសម្រាប់ឧបករណ៍ចាប់សញ្ញាដើម។ នៅក្នុងឯកសារ telegraf.conf ដូចគ្នា បន្ថែមកម្មវិធីជំនួយឧបករណ៍ចាប់សញ្ញាដើម inputs.jti_openconfig_telemetry ដែលវាលគឺស្ទើរតែដូចគ្នានឹង openconfig ។ ប្រើលេខសម្គាល់អតិថិជនពិសេសសម្រាប់ឧបករណ៍ចាប់សញ្ញានីមួយៗ។ នៅទីនេះយើងប្រើ "telegraf3" ។ ឈ្មោះតែមួយគត់ដែលប្រើនៅទីនេះសម្រាប់ឧបករណ៍ចាប់សញ្ញានេះគឺ "mem" (រូបភាពទី 7) ។

ជាចុងក្រោយ បន្ថែមកម្មវិធីជំនួយលទ្ធផល outputs.influxdb ដើម្បីផ្ញើទិន្នន័យឧបករណ៍ចាប់សញ្ញានេះទៅ InuxDB ។ នៅទីនេះ មូលដ្ឋានទិន្នន័យត្រូវបានដាក់ឈ្មោះថា "telegraf" ដែលមានឈ្មោះអ្នកប្រើប្រាស់ជា "inux" និងពាក្យសម្ងាត់ "inuxdb" (រូបភាពទី 8) ។

នៅពេលដែលអ្នកបានកែសម្រួលឯកសារ telegraf.conf សូមចាប់ផ្តើមសេវាកម្ម telegraf ឡើងវិញ។ ឥឡូវនេះ សូមពិនិត្យមើលនៅក្នុង InfluxDB CLI ដើម្បីប្រាកដថាការវាស់វែងត្រូវបានបង្កើតឡើងសម្រាប់ឧបករណ៍ចាប់សញ្ញាតែមួយគត់ទាំងអស់។ វាយបញ្ចូល "influx" ដើម្បីចូលទៅក្នុង InfluxDB CLI ។

ដូចដែលបានឃើញក្នុងរូប។ 9 បញ្ចូលប្រអប់បញ្ចូល influxDB ហើយប្រើមូលដ្ឋានទិន្នន័យ "telegraf" ។ ឈ្មោះតែមួយគត់ទាំងអស់ដែលបានផ្តល់ឱ្យឧបករណ៍ចាប់សញ្ញាត្រូវបានរាយបញ្ជីជារង្វាស់។
ដើម្បីមើលលទ្ធផលនៃការវាស់មួយគ្រាន់តែដើម្បីធ្វើឱ្យប្រាកដថាឯកសារតេឡេក្រាហ្វគឺត្រឹមត្រូវនិងឧបករណ៍ចាប់សញ្ញានេះកំពុងដំណើរការ, ប្រើពាក្យបញ្ជា "ជ្រើស * ពី cpu limit 1" ដូចបង្ហាញក្នុងរូបភាព 10 ។

រាល់ពេលដែលការផ្លាស់ប្តូរត្រូវបានធ្វើឡើងចំពោះឯកសារ telegraf.conf ត្រូវប្រាកដថាបញ្ឈប់ InuxDB ចាប់ផ្តើម Telegraf ឡើងវិញហើយបន្ទាប់មកចាប់ផ្តើម InuxDB ។
ចូលទៅកាន់ Grafana ពីកម្មវិធីរុករកតាមអ៊ីនធឺណិត ហើយបង្កើតផ្ទាំងគ្រប់គ្រង បន្ទាប់ពីធានាថាទិន្នន័យត្រូវបានប្រមូលត្រឹមត្រូវ។
ចូលទៅកាន់ការតភ្ជាប់ > InfuxDB > បន្ថែមប្រភពទិន្នន័យថ្មី។

- ផ្តល់ឈ្មោះទៅប្រភពទិន្នន័យនេះ។ នៅក្នុងការបង្ហាញនេះគឺ "test-1" ។
- នៅក្រោម HTTP stanza ប្រើ Ubuntu server IP និង 8086 port ។

- នៅក្នុងព័ត៌មានលម្អិត InfluxDB សូមប្រើឈ្មោះមូលដ្ឋានទិន្នន័យដូចគ្នា “telegraf” ហើយផ្តល់ឈ្មោះអ្នកប្រើប្រាស់ និងពាក្យសម្ងាត់របស់ម៉ាស៊ីនមេ Ubuntu ។
- ចុច រក្សាទុក & សាកល្បង។ ត្រូវប្រាកដថាអ្នកឃើញសារ "ជោគជ័យ"។

- នៅពេលដែលប្រភពទិន្នន័យត្រូវបានបន្ថែមដោយជោគជ័យ សូមចូលទៅកាន់ Dashboards ហើយចុច New ។ អនុញ្ញាតឱ្យយើងបង្កើតផ្ទាំងគ្រប់គ្រងមួយចំនួនដែលចាំបាច់សម្រាប់បន្ទុកការងារ AI/ML នៅក្នុងរបៀបកម្មវិធីនិពន្ធ។
Examples នៃ Sensor Graphs
ខាងក្រោមនេះជាអតីតamples នៃបញ្ជរសំខាន់ៗមួយចំនួនដែលចាំបាច់សម្រាប់ការត្រួតពិនិត្យបណ្តាញ AI/ML ។
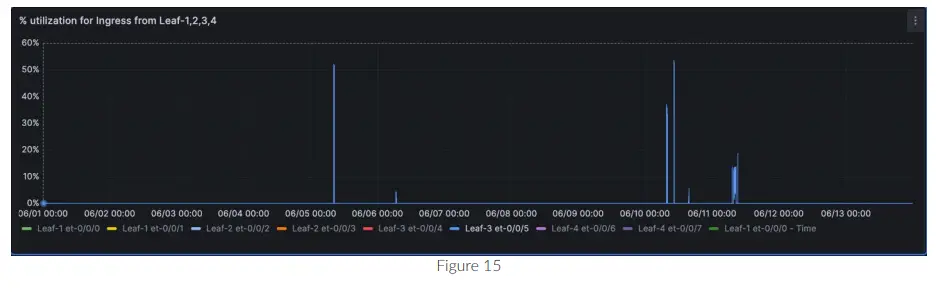
ភេនសិនtage ការប្រើប្រាស់សម្រាប់ចំណុចប្រទាក់ ingress et-0/0/0 នៅលើឆ្អឹងខ្នង-1

- ជ្រើសរើសប្រភពទិន្នន័យជា test-1 ។
- នៅក្នុងផ្នែក FROM ជ្រើសរើសការវាស់វែងជា "ចំណុចប្រទាក់" ។ នេះគឺជាឈ្មោះតែមួយគត់ដែលប្រើសម្រាប់ផ្លូវឧបករណ៍ចាប់សញ្ញានេះ។
- នៅក្នុងផ្នែក WHERE ជ្រើសរើសឧបករណ៍៖:tag, និងនៅក្នុង tag តម្លៃ ជ្រើសរើសឈ្មោះម៉ាស៊ីននៃកុងតាក់ នោះគឺឆ្អឹងខ្នង 1 ។
- នៅក្នុងផ្នែក SELECT ជ្រើសរើសសាខាឧបករណ៍ចាប់សញ្ញាដែលអ្នកចង់ត្រួតពិនិត្យ។ ក្នុងករណីនេះជ្រើសរើស “field(/interfaces/interface[if_name='et-0/0/0']/state/counters/if_in_1s_octes)”។ ឥឡូវនេះនៅក្នុងផ្នែកដូចគ្នាចុចលើ "+" ហើយបន្ថែមគណិតវិទ្យាគណនានេះ (/50000000000 * 100) ។ យើងកំពុងគណនាភាគរយជាមូលដ្ឋានtage ការប្រើប្រាស់ចំណុចប្រទាក់ 400G ។
- ត្រូវប្រាកដថា FORMAT គឺជា "ស៊េរីពេលវេលា" ហើយដាក់ឈ្មោះក្រាហ្វក្នុងផ្នែក ALIAS ។
 ការកាន់កាប់បណ្តោះអាសន្នខ្ពស់បំផុតសម្រាប់ជួរណាមួយ។
ការកាន់កាប់បណ្តោះអាសន្នខ្ពស់បំផុតសម្រាប់ជួរណាមួយ។

- ជ្រើសរើសប្រភពទិន្នន័យជា test-1 ។
- នៅក្នុងផ្នែក FROM ជ្រើសរើសការវាស់វែងជា "buffer"។
- នៅក្នុងផ្នែក WHERE មានវាលចំនួនបីដែលត្រូវបំពេញ។ ជ្រើសរើសឧបករណ៍៖:tag, និងនៅក្នុង tag តម្លៃជ្រើសរើសឈ្មោះម៉ាស៊ីននៃកុងតាក់ (ឧទាហរណ៍ឆ្អឹងខ្នង -1); ហើយជ្រើសរើស /cos/interfaces/interface/@name::tag ហើយជ្រើសរើសចំណុចប្រទាក់ (ឧទាហរណ៍ et- 0/0/0); ហើយជ្រើសរើសជួរផងដែរ /cos/interfaces/interface/queues/queue/@queue::tag ហើយជ្រើសរើសជួរលេខ 4 ។
- នៅក្នុងផ្នែក SELECT ជ្រើសរើសសាខាឧបករណ៍ចាប់សញ្ញាដែលអ្នកចង់ត្រួតពិនិត្យ។ ក្នុងករណីនេះជ្រើសរើស "វាល(/cos/interfaces/interface/queues/queue/PeakBuferOccupancy)"។
- ត្រូវប្រាកដថា FORMAT គឺជា "ស៊េរីពេលវេលា" ហើយដាក់ឈ្មោះក្រាហ្វក្នុងផ្នែក ALIAS ។
អ្នកអាចប្រមូលផ្តុំទិន្នន័យសម្រាប់ចំណុចប្រទាក់ច្រើននៅលើក្រាហ្វដូចគ្នាដូចដែលឃើញក្នុងរូបភាពទី 17 សម្រាប់ et-0/0/0, et-0/0/1, et-0/0/2 ជាដើម។

PFC និង ECN មានន័យថាដេរីវេ

សម្រាប់ការស្វែងរកដេរីវេមធ្យម (ភាពខុសគ្នានៃតម្លៃក្នុងចន្លោះពេលមួយ) សូមប្រើរបៀបសំណួរឆៅ។
នេះគឺជាសំណួរដែលហូរចូលដែលយើងបានប្រើដើម្បីស្វែងរកដេរីវេមធ្យមរវាងតម្លៃ PFC ពីរនៅលើ et-0/0/0 នៃ Spine-1 ក្នុងមួយវិនាទី។
SELECT derivative(mean(“/interfaces/interface[if_name='et-0/0/0′]/state/pfc-counter/tx_pkts”), 1s) ពី “interface” កន្លែងណា (“ឧបករណ៍”::tag = 'Spine-1') និង $timeFilter GROUP តាមពេលវេលា($interval)

SELECT derivative(mean(“/interfaces/interface[if_name='et-0/0/8′]/state/error-counters/ecn_ce_marked_pkts”), 1s) ពី “ចំណុចប្រទាក់” កន្លែងណា (“ឧបករណ៍”::tag = 'Spine-1') និង $timeFilter GROUP តាមពេលវេលា($interval)

កំហុសប្រភពបញ្ចូលមានន័យថា ដេរីវេ

សំណួរឆៅសម្រាប់កំហុសធនធានមានន័យថាដេរីវេគឺ៖
SELECT derivative(mean(“/interfaces/interface[if_name='et-0/0/0′]/state/error-counters/if_in_resource_errors”), 1s) ពី “ចំណុចប្រទាក់” កន្លែងណា (“ឧបករណ៍”::tag = 'Spine-1') និង $timeFilter GROUP តាមពេលវេលា($interval)

តំណក់ទឹកមានន័យថាជានិស្សន្ទវត្ថុ

សំណួរឆៅសម្រាប់ការទម្លាក់កន្ទុយមានន័យថាដេរីវេគឺ៖
SELECT derivative(មានន័យថា(“/cos/interfaces/interface/queues/queue/tailDropBytes”), 1s) ពី “buffer” កន្លែងណា (“ឧបករណ៍”::tag = 'Leaf-1' និង “/cos/interfaces/interface/@name”::tag = 'et-0/0/0' និង “/cos/interfaces/interface/queues/queue/@queue”::tag = '4') និង $timeFilter GROUP តាមពេលវេលា($__interval) បំពេញ(null)
ការប្រើប្រាស់ស៊ីភីយូ

- ជ្រើសរើសប្រភពទិន្នន័យជា test-1 ។
- នៅក្នុងផ្នែក FROM ជ្រើសរើសការវាស់វែងជា "newcpu"
- នៅកន្លែងណា មានវាលបីដែលត្រូវបំពេញ។ ជ្រើសរើសឧបករណ៍៖:tag និងនៅក្នុង tag តម្លៃជ្រើសរើសឈ្មោះម៉ាស៊ីននៃកុងតាក់ (ឧទាហរណ៍ឆ្អឹងខ្នង -1) ។ ហើយនៅក្នុង /components/component/properties/property/name:tagហើយជ្រើសរើស cpuutilization-total AND នៅក្នុងឈ្មោះ::tag ជ្រើសរើស RE0 ។
- នៅក្នុងផ្នែក SELECT ជ្រើសរើសសាខាឧបករណ៍ចាប់សញ្ញាដែលអ្នកចង់ត្រួតពិនិត្យ។ ក្នុងករណីនេះ ជ្រើសរើស "វាល(ស្ថានភាព/តម្លៃ)"។

សំណួរឆៅសម្រាប់ការស្វែងរកដេរីវេមិនអវិជ្ជមាននៃ tail drops សម្រាប់ការប្តូរច្រើននៅលើចំណុចប្រទាក់ច្រើនក្នុងមួយប៊ីត/វិនាទី។
SELECT non_negative_derivative(mean(“/cos/interfaces/interface/queues/queue/tailDropBytes”), 1s)*8 ពី “buffer” កន្លែងណា (ឧបករណ៍៖:tag =~ /^Spine-[1-2]$/) និង (“/cos/interfaces/interface/@name”::tag =~ /et-0\/0\/[0-9]/ ឬ “/cos/interfaces/interface/@name”::tag=~/et-0\/0\/1[0-5]/) និង $timeFilter GROUP តាមពេលវេលា ($__interval) ឧបករណ៍៖៖tag បំពេញ(ទទេ)

ទាំងនេះគឺជាអតីតមួយចំនួនamples នៃក្រាហ្វដែលអាចត្រូវបានបង្កើតសម្រាប់ការត្រួតពិនិត្យបណ្តាញ AI/ML ។
សង្ខេប
ក្រដាសនេះបង្ហាញពីវិធីសាស្រ្តនៃការទាញទិន្នន័យ telemetry និងមើលឃើញវាដោយបង្កើតក្រាហ្វ។ ក្រដាសនេះនិយាយជាពិសេសអំពីឧបករណ៍ចាប់សញ្ញា AI/ML ទាំងឧបករណ៍ចាប់សញ្ញាដើម និងបើកចំហ ប៉ុន្តែការដំឡើងអាចប្រើសម្រាប់ឧបករណ៍ចាប់សញ្ញាគ្រប់ប្រភេទ។ យើងក៏បានរួមបញ្ចូលផងដែរនូវដំណោះស្រាយសម្រាប់បញ្ហាជាច្រើនដែលអ្នកអាចប្រឈមមុខនៅពេលបង្កើតការដំឡើង។ ជំហាន និងលទ្ធផលដែលបង្ហាញក្នុងក្រដាសនេះគឺជាក់លាក់ចំពោះកំណែនៃ TIG stack ដែលបានរៀបរាប់ពីមុន។ វាអាចផ្លាស់ប្តូរអាស្រ័យលើកំណែកម្មវិធី ឧបករណ៍ចាប់សញ្ញា និងកំណែ Junos ។
ឯកសារយោង
Juniper Yang Data Model Explorer សម្រាប់ជម្រើសឧបករណ៍ចាប់សញ្ញាទាំងអស់។
https://apps.juniper.net/ydm-explorer/
វេទិកា Openconfig សម្រាប់ឧបករណ៍ចាប់សញ្ញា openconfigg
https://www.openconfig.net/projects/models/
![]()
ការិយាល័យកណ្តាលរបស់ក្រុមហ៊ុន និងផ្នែកលក់
Juniper Networks, Inc.
1133 វិធីនៃការច្នៃប្រឌិត
Sunnyvale, CA 94089 សហរដ្ឋអាមេរិក
ទូរស័ព្ទ៖ 888. JUNIPER (888.586.4737)
ឬ +1.408.745.2000
ទូរសារ៖ +1.408.745.2100
www.juniper.net
APAC និង EMEA ទីស្នាក់ការកណ្តាល
Juniper Networks International BV
Boeing Avenue 240
១១១៩ PZ Schiphol-Rijk
ទីក្រុង Amsterdam ប្រទេសហូឡង់
ទូរស័ព្ទ៖ +31.207.125.700
ទូរសារ៖ +31.207.125.701
រក្សាសិទ្ធិ 2023 Juniper Networks ។ Inc. Ail រក្សាសិទ្ធិ។ Juniper Networks, និមិត្តសញ្ញា Juniper Networks, Juniper, Junos និងពាណិជ្ជសញ្ញាផ្សេងទៀតគឺជាពាណិជ្ជសញ្ញាដែលបានចុះបញ្ជីរបស់ Juniper Networks ។ Inc. និង/ឬសាខារបស់ខ្លួននៅសហរដ្ឋអាមេរិក និងប្រទេសដទៃទៀត។ ឈ្មោះផ្សេងទៀតអាចជាពាណិជ្ជសញ្ញារបស់ម្ចាស់រៀងៗខ្លួន។ Juniper Networks មិនទទួលខុសត្រូវចំពោះភាពមិនត្រឹមត្រូវណាមួយនៅក្នុងឯកសារនេះទេ។ Juniper Networks រក្សាសិទ្ធិក្នុងការផ្លាស់ប្តូរ។ កែប្រែ។ ផ្ទេរ ឬកែប្រែការបោះពុម្ពផ្សាយនេះដោយមិនចាំបាច់ជូនដំណឹងជាមុន។
ផ្ញើមតិកែលម្អទៅ៖ design-center-comments@juniper.net V1.0/240807/ejm5-telemetry-junos-ai-ml
ឯកសារ/ធនធាន
 |
Juniper NETWORKS Telemetry In Junos សម្រាប់កម្មវិធី AI ML Workloads [pdf] ការណែនាំអ្នកប្រើប្រាស់ Telemetry In Junos សម្រាប់ AI ML Workloads Software, Junos សម្រាប់កម្មវិធី AI ML Workloads Software, AI ML Workloads Software, Workloads Software, Software |