![]() Telemetria w Junos dla obciążeń AI/ML
Telemetria w Junos dla obciążeń AI/ML
Autor: Shalini Mukherjee
Wstęp
Ponieważ ruch klastra AI wymaga bezstratnych sieci o wysokiej przepustowości i niskim opóźnieniu, kluczowym elementem sieci AI jest zbieranie danych monitorujących. Junos Telemetry umożliwia szczegółowe monitorowanie kluczowych wskaźników wydajności, w tym progów i liczników do zarządzania przeciążeniem i równoważenia obciążenia ruchu. Sesje gRPC obsługują przesyłanie strumieniowe danych telemetrycznych. gRPC to nowoczesne, wysokowydajne środowisko typu open source, które opiera się na transporcie HTTP/2. Umożliwia natywne dwukierunkowe przesyłanie strumieniowe i obejmuje elastyczne niestandardowe metadane w nagłówkach żądania. Pierwszym krokiem w telemetrii jest wiedza, jakie dane mają być zbierane. Następnie możemy analizować te dane w różnych formatach. Po zebraniu danych ważne jest, aby przedstawić je w formacie, który jest łatwy do monitorowania, podejmowania decyzji i ulepszania oferowanej usługi. W tym artykule używamy stosu telemetrycznego składającego się z Telegraf, InfluxDB i Grafana. Ten stos telemetryczny zbiera dane przy użyciu modelu push. Tradycyjne modele pull są zasobochłonne, wymagają ręcznej interwencji i mogą zawierać luki informacyjne w zbieranych danych. Modele push pokonują te ograniczenia, dostarczając dane asynchronicznie. Wzbogacają dane, wykorzystując przyjazne dla użytkownika tags i imiona. Gdy dane uzyskają bardziej czytelny format, przechowujemy je w bazie danych i wykorzystujemy w interaktywnej wizualizacji web aplikacja do analizy sieci. Rysunek 1 pokazuje nam, jak ten stos jest zaprojektowany do wydajnego zbierania, przechowywania i wizualizacji danych, od urządzeń sieciowych przesyłających dane do kolektora po dane wyświetlane na pulpitach nawigacyjnych w celu analizy.

Stos TIG
Do zainstalowania całego oprogramowania, w tym stosu TIG, użyliśmy serwera Ubuntu.
telegraf
Do zbierania danych używamy Telegrafa na serwerze Ubuntu z systemem 22.04.2. Wersja Telegrafa uruchomiona w tej wersji demonstracyjnej to 1.28.5.
Telegraf to oparty na wtyczkach agent serwera do zbierania i raportowania metryk. Używa procesora plugins wzbogacać i normalizować dane. Wyjście plugins służą do wysyłania tych danych do różnych magazynów danych. W tym dokumencie używamy dwóch plugins: jeden dla czujników openconfig, a drugi dla natywnych czujników Juniper.
InfluxDB
Aby przechowywać dane w bazie danych szeregów czasowych, używamy InfluxDB. Wtyczka wyjściowa w Telegrafie wysyła dane do InfluxDB, który przechowuje je w wysoce wydajny sposób. Używamy V1.8, ponieważ nie ma CLI dla V2 i nowszych.
Grafana
Grafana służy do wizualizacji tych danych. Grafana pobiera dane z InfluxDB i pozwala użytkownikom tworzyć bogate i interaktywne pulpity nawigacyjne. Tutaj uruchamiamy wersję 10.2.2.
Konfiguracja na przełączniku
Aby wdrożyć ten stos, najpierw musimy skonfigurować przełącznik, jak pokazano na rysunku 2. Użyliśmy portu 50051. Można użyć dowolnego portu. Zaloguj się do przełącznika QFX i dodaj następującą konfigurację.

Notatka: Ta konfiguracja jest przeznaczona dla laboratoriów/POC, ponieważ hasło jest przesyłane w postaci zwykłego tekstu. Użyj SSL, aby tego uniknąć.
Środowisko

Nginx
Jest to potrzebne, jeśli nie możesz udostępnić portu, na którym hostowana jest Grafana. Następnym krokiem jest zainstalowanie nginx na serwerze Ubuntu, aby służył jako odwrotny agent proxy. Po zainstalowaniu nginx dodaj wiersze pokazane na rysunku 4 do pliku „default” i przenieś plik z /etc/nginx do /etc/nginx/sites-enabled.


Upewnij się, że zapora sieciowa jest dostosowana tak, aby zapewnić pełny dostęp do usługi nginx, jak pokazano na rysunku 5.

Po zainstalowaniu Nginx i wprowadzeniu wymaganych zmian powinniśmy mieć dostęp do Grafany z poziomu pliku web przeglądarkę, korzystając z adresu IP serwera Ubuntu, na którym zainstalowane jest całe oprogramowanie.
W Grafanie występuje mały błąd, który nie pozwala zresetować domyślnego hasła. Jeśli napotkasz ten problem, wykonaj te czynności.
Kroki, które należy wykonać na serwerze Ubuntu, aby ustawić hasło w Grafanie:
- Przejdź do /var/lib/grafana/grafana.db
- Zainstaluj sqllite3
o sudo apt install sqlite3 - Uruchom to polecenie na swoim terminalu
o sqlite3 grafana.db - Otwiera się wiersz poleceń SQLite; uruchom następujące zapytanie:
>usuń z użytkownika, gdzie login='admin' - Uruchom ponownie grafana i wpisz admin jako nazwę użytkownika i hasło. Zostaniesz poproszony o podanie nowego hasła.
Po zainstalowaniu całego oprogramowania należy utworzyć plik konfiguracyjny w Telegrafie, który pomoże pobrać dane telemetryczne z przełącznika i przesłać je do InfluxDB.
Wtyczka czujnika Openconfig
Na serwerze Ubuntu edytuj plik /etc/telegraf/telegraf.conf, aby dodać wszystkie wymagane plugins i czujników. W przypadku czujników openconfig używamy wtyczki gNMI pokazanej na rysunku 6. W celach demonstracyjnych dodaj nazwę hosta jako „spine1”, numer portu „50051” używany dla gRPC, nazwę użytkownika i hasło przełącznika oraz liczbę sekund ponownego wybierania w przypadku awarii.
W sekcji subskrypcji dodaj unikalną nazwę „cpu” dla tego konkretnego czujnika, ścieżkę czujnika i interwał czasowy pobierania tych danych z przełącznika. Dodaj tę samą wtyczkę inputs.gnmi i inputs.gnmi.subscription dla wszystkich otwartych czujników konfiguracji. (Rysunek 6)

Natywna wtyczka czujnika
To jest wtyczka interfejsu telemetrii Juniper używana dla natywnych czujników. W tym samym pliku telegraf.conf dodaj natywną wtyczkę czujnika inputs.jti_openconfig_telemetry, gdzie pola są prawie takie same jak w pliku openconfig. Użyj unikalnego identyfikatora klienta dla każdego czujnika; tutaj używamy „telegraf3”. Unikalna nazwa użyta tutaj dla tego czujnika to „mem” (Rysunek 7).

Na koniec dodaj wtyczkę wyjściową outputs.influxdb, aby wysłać te dane czujnika do InfluxDB. Tutaj baza danych nosi nazwę „telegraf”, a nazwa użytkownika to „influx” i hasło „influxdb” (Rysunek 8).

Po edycji pliku telegraf.conf uruchom ponownie usługę telegraf. Teraz sprawdź w InfluxDB CLI, czy pomiary zostały utworzone dla wszystkich unikalnych czujników. Wpisz „influx”, aby wejść do InfluxDB CLI.

Jak widać na Rysunku 9, wprowadź monit influxDB i użyj bazy danych „telegraf”. Wszystkie unikalne nazwy nadane czujnikom są wymienione jako pomiary.
Aby zobaczyć wynik dowolnego pomiaru, a także upewnić się, że plik telegrafu jest poprawny i czujnik działa, należy użyć polecenia „select * from cpu limit 1”, jak pokazano na rysunku 10.

Za każdym razem, gdy wprowadzasz zmiany w pliku telegraf.conf, pamiętaj o zatrzymaniu InfluxDB, ponownym uruchomieniu Telegrafa, a następnie ponownym uruchomieniu InfluxDB.
Zaloguj się do Grafany z poziomu przeglądarki i utwórz pulpity nawigacyjne po upewnieniu się, że dane są zbierane prawidłowo.
Przejdź do Połączenia > InfuxDB > Dodaj nowe źródło danych.

- Podaj nazwę tego źródła danych. W tej wersji demonstracyjnej jest to „test-1”.
- W sekcji HTTP użyj adresu IP serwera Ubuntu i portu 8086.

- W szczegółach InfluxDB użyj tej samej nazwy bazy danych, „telegraf”, i podaj nazwę użytkownika i hasło serwera Ubuntu.
- Kliknij Zapisz i przetestuj. Upewnij się, że widzisz komunikat „pomyślnie”.

- Po pomyślnym dodaniu źródła danych przejdź do Dashboards i kliknij New (Nowy). Utwórzmy kilka dashboardów, które są niezbędne dla obciążeń AI/ML w trybie edytora.
Examppliki wykresów czujnika
Oto byłyamppliki niektórych głównych liczników niezbędnych do monitorowania sieci AI/ML.
ProcenttagWykorzystanie interfejsu wejściowego et-0/0/0 na kręgosłupie-1

- Wybierz źródło danych jako test-1.
- W sekcji FROM wybierz pomiar jako „interface”. Jest to unikalna nazwa używana dla tej ścieżki czujnika.
- W sekcji GDZIE wybierz urządzenie:tagi w tag wartość, wybierz nazwę hosta przełącznika, czyli spine1.
- W sekcji SELECT wybierz gałąź czujnika, którą chcesz monitorować; w tym przypadku wybierz „field(/interfaces/interface[if_name='et-0/0/0']/state/counters/if_in_1s_octets)”. Teraz w tej samej sekcji kliknij „+” i dodaj tę kalkulację matematyczną (/50000000000 * 100). Zasadniczo obliczamy procenttagWykorzystanie interfejsu 400G.
- Upewnij się, że FORMAT jest ustawiony na „seria czasowa” i nadaj wykresowi nazwę w sekcji ALIAS.
 Szczytowe zapełnienie bufora dla dowolnej kolejki
Szczytowe zapełnienie bufora dla dowolnej kolejki

- Wybierz źródło danych jako test-1.
- W sekcji OD wybierz pomiar jako „bufor”.
- W sekcji WHERE znajdują się trzy pola do wypełnienia. Wybierz urządzenie::tagi w tag wartość wybierz nazwę hosta przełącznika (np. spine-1); ORAZ wybierz /cos/interfaces/interface/@name::tag i wybierz interfejs (np. et- 0/0/0); ORAZ wybierz także kolejkę, /cos/interfaces/interface/queues/queue/@queue::tag i wybierz kolejkę numer 4.
- W sekcji SELECT wybierz gałąź czujnika, którą chcesz monitorować; w tym przypadku wybierz „field(/cos/interfaces/interface/queues/queue/PeakBufferOccupancy)”.
- Upewnij się, że FORMAT jest ustawiony na „seria czasowa” i nadaj wykresowi nazwę w sekcji ALIAS.
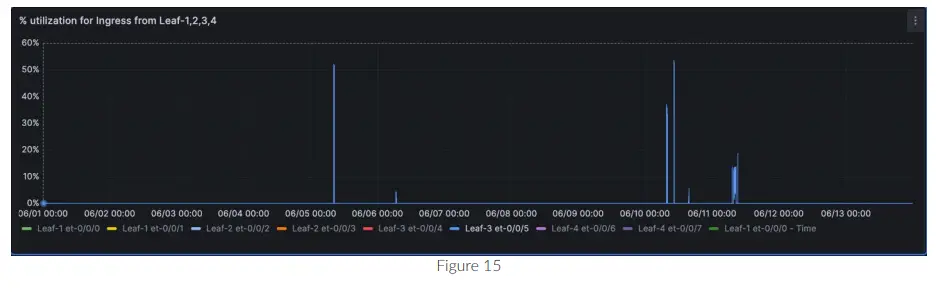
Dane dla wielu interfejsów można zestawiać na tym samym wykresie, jak pokazano na rysunku 17, dla et-0/0/0, et-0/0/1, et-0/0/2 itd.

PFC i ECN oznaczają pochodną

Aby znaleźć średnią pochodną (różnicę wartości w określonym przedziale czasowym), należy użyć trybu zapytania surowego.
To jest zapytanie napływowe, którego użyliśmy do znalezienia średniej pochodnej między dwiema wartościami PFC na et-0/0/0 Spine-1 w ciągu sekundy.
WYBIERZ pochodną(średnia(“/interfejsy/interfejs[if_name='et-0/0/0′]/stan/licznik-pfc/tx_pkts”), 1s) Z “interfejs” GDZIE (“urządzenie”::tag = 'Spine-1') ORAZ $timeFilter GROUP WEDŁUG czasu($interval)

WYBIERZ pochodną(średnia(“/interfejsy/interfejs[if_name='et-0/0/8′]/stan/liczniki-błędów/pkt_oznaczone_ecn_ce”), 1s) Z “interfejs” GDZIE (“urządzenie”::tag = 'Spine-1') ORAZ $timeFilter GROUP WEDŁUG czasu($interval)

Błędy zasobów wejściowych oznaczają pochodną

Surowe zapytanie o średnią pochodną błędów zasobów wygląda następująco:
WYBIERZ pochodną(średnia(“/interfejsy/interfejs[if_name='et-0/0/0′]/stan/liczniki-błędów/błędy_jeśli_w_zasobach”), 1s) Z “interfejs” GDZIE (“urządzenie”::tag = 'Spine-1') ORAZ $timeFilter GROUP WEDŁUG czasu($interval)

Ogon oznacza pochodną

Surowe zapytanie o spadek ogona oznacza pochodną:
WYBIERZ pochodną(średnia(“/cos/interfejsy/interfejs/kolejki/kolejka/ogonDropBytes”), 1s) Z “bufor” GDZIE (“urządzenie”::tag = 'Liść-1' ORAZ „/cos/interfaces/interface/@name”::tag = 'et-0/0/0' ORAZ „/cos/interfaces/interface/queues/queue/@queue”::tag = '4') I $timeFilter GRUPUJ WEDŁUG czasu($__interval) wypelnij(null)
Wykorzystanie procesora

- Wybierz źródło danych jako test-1.
- W sekcji OD wybierz pomiar jako „newcpu”
- W polu WHERE są trzy pola do wypełnienia. Wybierz urządzenie::tag i w tag wartość wybierz nazwę hosta przełącznika (np. spine-1). ORAZ w /components/component/properties/property/name:tagi wybierz cpuutilization-total ORAZ w nazwie::tag wybierz RE0.
- W sekcji SELECT wybierz gałąź czujnika, którą chcesz monitorować. W tym przypadku wybierz „field(state/value)”.

Surowe zapytanie mające na celu znalezienie nieujemnej pochodnej spadku końcowego dla wielu przełączeń na wielu interfejsach w bitach na sekundę.
WYBIERZ nieujemną_pochodną(średnia(“/cos/interfejsy/interfejs/kolejki/kolejka/tailDropBytes”), 1s)*8 Z “bufora” GDZIE (urządzenie::tag =~ /^Spine-[1-2]$/) i („/cos/interfaces/interface/@name”::tag =~ /et-0\/0\/[0-9]/ lub „/cos/interfaces/interface/@name”::tag=~/et-0\/0\/1[0-5]/) I $timeFilter GRUPUJ WEDŁUG time($__interval),device::tag wypełnij(null)

To byli niektórzy z byłychamppliki wykresów, które można utworzyć w celu monitorowania sieci AI/ML.
Streszczenie
W tym artykule zilustrowano metodę pobierania danych telemetrycznych i ich wizualizacji poprzez tworzenie wykresów. W tym artykule omówiono konkretnie czujniki AI/ML, zarówno natywne, jak i openconfig, ale konfiguracja może być używana dla wszystkich rodzajów czujników. Zawarliśmy również rozwiązania dla wielu problemów, z którymi możesz się spotkać podczas tworzenia konfiguracji. Kroki i wyniki przedstawione w tym artykule są specyficzne dla wersji stosu TIG wymienionych wcześniej. Mogą ulec zmianie w zależności od wersji oprogramowania, czujników i wersji Junos.
Odniesienia
Juniper Yang Data Model Explorer dla wszystkich opcji czujników
https://apps.juniper.net/ydm-explorer/
Forum Openconfig dla czujników Openconfig
https://www.openconfig.net/projects/models/
![]()
Centrala korporacyjna i sprzedażowa
Juniper Networks, Inc.
1133 sposób innowacji
Sunnyvale, CA 94089 Stany Zjednoczone
Telefon: 888. JUNIPER (888.586.4737)
lub +1.408.745.2000
Faks: +1.408.745.2100
www.juniper.net
Centrale APAC i EMEA
Juniper Networks International BV
Aleja Boeinga 240
1119 PZ Schiphol-Rijk
Amsterdam, Holandia
Telefon: +31.207.125.700
Faks: +31.207.125.701
Prawa autorskie 2023 Juniper Networks. Inc. Wszystkie prawa zastrzeżone. Juniper Networks, logo Juniper Networks, Juniper, Junos i inne znaki towarowe są zarejestrowanymi znakami towarowymi Juniper Networks. inc. i/lub jej podmiotów stowarzyszonych w Stanach Zjednoczonych i innych krajach. Inne nazwy mogą być znakami towarowymi ich właścicieli. Juniper Networks nie ponosi odpowiedzialności za jakiekolwiek nieścisłości w tym dokumencie. Juniper Networks zastrzega sobie prawo do zmiany, modyfikacji, przeniesienia lub w inny sposób rewizji tej publikacji bez powiadomienia.
Wyślij opinię na adres: design-center-comments@juniper.net Wersja 1.0/240807/ejm5-telemetry-junos-ai-ml
Dokumenty / Zasoby
 |
Telemetria Juniper NETWORKS w oprogramowaniu Junos dla obciążeń AI ML [plik PDF] Instrukcja użytkownika Telemetria w oprogramowaniu Junos do obsługi obciążeń AI ML, oprogramowanie do obsługi obciążeń AI ML Junos, oprogramowanie do obsługi obciążeń AI ML, oprogramowanie do obsługi obciążeń, oprogramowanie |