![]() Telemetry ໃນ Junos ສໍາລັບ AI/ML Workloads
Telemetry ໃນ Junos ສໍາລັບ AI/ML Workloads
ຜູ້ຂຽນ: Shalini Mukherjee
ແນະນຳ
ເນື່ອງຈາກ AI cluster traffic ຕ້ອງການເຄືອຂ່າຍທີ່ສູນເສຍການສົ່ງຂໍ້ມູນສູງ ແລະ latency ຕໍ່າ, ອົງປະກອບທີ່ສໍາຄັນຂອງເຄືອຂ່າຍ AI ແມ່ນການເກັບກໍາຂໍ້ມູນການຕິດຕາມ. Junos Telemetry ເຮັດໃຫ້ການຕິດຕາມ granular ຂອງຕົວຊີ້ວັດການປະຕິບັດທີ່ສໍາຄັນ, ລວມທັງຂອບເຂດແລະ counters ສໍາລັບການຄຸ້ມຄອງຄວາມແອອັດແລະການດຸ່ນດ່ຽງການໂຫຼດ. ກອງປະຊຸມ gRPC ສະຫນັບສະຫນູນການຖ່າຍທອດຂໍ້ມູນ telemetry. gRPC ເປັນໂຄງຮ່າງການທີ່ທັນສະໄໝ, ເປີດແຫຼ່ງ, ປະສິດທິພາບສູງທີ່ສ້າງຂຶ້ນໃນການຂົນສົ່ງ HTTP/2. ມັນສ້າງຄວາມເຂັ້ມແຂງຄວາມສາມາດໃນການຖ່າຍທອດແບບ bidirectional ພື້ນເມືອງແລະປະກອບມີ metadata ທີ່ສາມາດປັບແຕ່ງໄດ້ໃນສ່ວນຫົວຄໍາຮ້ອງຂໍ. ຂັ້ນຕອນເບື້ອງຕົ້ນໃນ telemetry ແມ່ນເພື່ອຮູ້ວ່າຂໍ້ມູນໃດທີ່ຈະເກັບກໍາ. ຫຼັງຈາກນັ້ນພວກເຮົາສາມາດວິເຄາະຂໍ້ມູນນີ້ໃນຮູບແບບຕ່າງໆ. ເມື່ອພວກເຮົາເກັບກໍາຂໍ້ມູນ, ມັນເປັນສິ່ງສໍາຄັນທີ່ຈະນໍາສະເຫນີມັນໃນຮູບແບບທີ່ງ່າຍຕໍ່ການຕິດຕາມ, ຕັດສິນໃຈແລະປັບປຸງການບໍລິການທີ່ຖືກສະເຫນີ. ໃນເອກະສານນີ້, ພວກເຮົາໃຊ້ stack telemetry ປະກອບດ້ວຍ Telegraf, InfluxDB, ແລະ Grafana. stack telemetry ນີ້ເກັບກໍາຂໍ້ມູນໂດຍໃຊ້ຕົວແບບ push. ຮູບແບບການດຶງແບບດັ້ງເດີມແມ່ນໃຊ້ຊັບພະຍາກອນຫຼາຍ, ຮຽກຮ້ອງໃຫ້ມີການແຊກແຊງດ້ວຍຕົນເອງ, ແລະສາມາດປະກອບມີຊ່ອງຫວ່າງຂໍ້ມູນໃນຂໍ້ມູນທີ່ເຂົາເຈົ້າເກັບກໍາ. ແບບ Push ເອົາຊະນະຂໍ້ຈໍາກັດເຫຼົ່ານີ້ໂດຍການສົ່ງຂໍ້ມູນແບບ asynchronous. ພວກເຂົາເຈົ້າເສີມຂະຫຍາຍຂໍ້ມູນໂດຍການນໍາໃຊ້ທີ່ເປັນມິດກັບຜູ້ໃຊ້ tags ແລະຊື່. ເມື່ອຂໍ້ມູນຢູ່ໃນຮູບແບບທີ່ສາມາດອ່ານໄດ້ຫຼາຍຂຶ້ນ, ພວກເຮົາເກັບມັນໄວ້ໃນຖານຂໍ້ມູນແລະໃຊ້ມັນໃນການສະແດງພາບແບບໂຕ້ຕອບ web ຄໍາຮ້ອງສະຫມັກສໍາລັບການວິເຄາະເຄືອຂ່າຍ. ຮູບ. 1 ສະແດງໃຫ້ເຫັນພວກເຮົາວິທີການ stack ນີ້ຖືກອອກແບບມາສໍາລັບການເກັບຂໍ້ມູນ, ການເກັບຮັກສາ, ແລະການເບິ່ງເຫັນທີ່ມີປະສິດທິພາບ, ຈາກອຸປະກອນເຄືອຂ່າຍທີ່ຊຸກດັນໃຫ້ຂໍ້ມູນໄປຫາຕົວເກັບລວບລວມໄປຫາຂໍ້ມູນທີ່ສະແດງຢູ່ໃນ dashboards ສໍາລັບການວິເຄາະ.

TIG Stack
ພວກເຮົາໄດ້ໃຊ້ເຊີບເວີ Ubuntu ເພື່ອຕິດຕັ້ງຊອບແວທັງໝົດລວມທັງ TIG stack.
ໂທລະເລກ
ເພື່ອເກັບກຳຂໍ້ມູນ, ພວກເຮົາໃຊ້ Telegraf ໃນເຊີບເວີ Ubuntu ທີ່ແລ່ນ 22.04.2. ລຸ້ນ Telegraf ທີ່ແລ່ນຢູ່ໃນສາທິດນີ້ແມ່ນ 1.28.5.
Telegraf ແມ່ນຕົວແທນເຊີບເວີທີ່ຂັບເຄື່ອນດ້ວຍ plugin ສໍາລັບການເກັບກໍາແລະການລາຍງານ metrics. ມັນໃຊ້ໂປເຊດເຊີ plugins ເພື່ອເສີມສ້າງ ແລະປັບຂໍ້ມູນໃຫ້ເປັນປົກກະຕິ. ຜົນຜະລິດ plugins ຖືກນໍາໃຊ້ເພື່ອສົ່ງຂໍ້ມູນນີ້ໄປຫາບ່ອນເກັບຂໍ້ມູນຕ່າງໆ. ໃນເອກະສານນີ້ພວກເຮົາໃຊ້ສອງ plugins: ອັນໜຶ່ງສຳລັບເຊັນເຊີ openconfig ແລະອີກອັນໜຶ່ງສຳລັບເຊັນເຊີພື້ນເມືອງ Juniper.
InfluxDB
ເພື່ອເກັບຂໍ້ມູນໄວ້ໃນຖານຂໍ້ມູນຊຸດເວລາ, ພວກເຮົາໃຊ້ InfluxDB. ປັ໊ກອິນຜົນຜະລິດໃນ Telegraf ສົ່ງຂໍ້ມູນໄປຍັງ InuxDB, ເຊິ່ງເກັບຮັກສາມັນໄວ້ໃນລັກສະນະທີ່ມີປະສິດທິພາບສູງ. ພວກເຮົາກໍາລັງໃຊ້ V1.8 ເນື່ອງຈາກບໍ່ມີ CLI ປະຈຸບັນສໍາລັບ V2 ແລະຂ້າງເທິງ.
ກຣາຟານາ
Grafana ຖືກນໍາໃຊ້ເພື່ອສະແດງຂໍ້ມູນນີ້. Grafana ດຶງຂໍ້ມູນຈາກ InfluxDB ແລະອະນຸຍາດໃຫ້ຜູ້ໃຊ້ສ້າງ dashboards ທີ່ອຸດົມສົມບູນແລະການໂຕ້ຕອບ. ນີ້, ພວກເຮົາກໍາລັງແລ່ນສະບັບ 10.2.2.
ການຕັ້ງຄ່າໃນສະວິດ
ເພື່ອປະຕິບັດ stack ນີ້, ທໍາອິດພວກເຮົາຈໍາເປັນຕ້ອງໄດ້ configure ສະຫຼັບດັ່ງທີ່ສະແດງຢູ່ໃນຮູບ 2. ພວກເຮົາໄດ້ນໍາໃຊ້ພອດ 50051. ພອດໃດກໍ່ສາມາດນໍາໃຊ້ໄດ້ທີ່ນີ້. ເຂົ້າສູ່ລະບົບ QFX switch ແລະເພີ່ມການຕັ້ງຄ່າຕໍ່ໄປນີ້.

ໝາຍເຫດ: ການຕັ້ງຄ່ານີ້ແມ່ນສໍາລັບຫ້ອງທົດລອງ / POCs ເປັນລະຫັດຜ່ານແມ່ນໄດ້ຮັບການສົ່ງໃນຂໍ້ຄວາມທີ່ຈະແຈ້ງ. ໃຊ້ SSL ເພື່ອຫຼີກເວັ້ນການນີ້.
ສະພາບແວດລ້ອມ

Nginx
ນີ້ແມ່ນຈໍາເປັນຖ້າຫາກວ່າທ່ານບໍ່ສາມາດເປີດເຜີຍພອດທີ່ Grafana ເປັນເຈົ້າພາບ. ຂັ້ນຕອນຕໍ່ໄປແມ່ນການຕິດຕັ້ງ nginx ເທິງເຊີບເວີ Ubuntu ເພື່ອຮັບໃຊ້ເປັນຕົວແທນຕົວແທນ reverse. ເມື່ອ nginx ຖືກຕິດຕັ້ງ, ເພີ່ມເສັ້ນສະແດງໃນຮູບທີ 4 ໄປຫາໄຟລ໌ "ເລີ່ມຕົ້ນ" ແລະຍ້າຍໄຟລ໌ຈາກ /etc/nginx ໄປ /etc/nginx/sites-enabled.


ໃຫ້ແນ່ໃຈວ່າ firewall ໄດ້ຖືກປັບເພື່ອໃຫ້ການເຂົ້າເຖິງການບໍລິການ nginx ຢ່າງເຕັມທີ່ຕາມທີ່ສະແດງຢູ່ໃນຮູບ 5.

ເມື່ອ nginx ຖືກຕິດຕັ້ງແລະການປ່ຽນແປງທີ່ຈໍາເປັນ, ພວກເຮົາຄວນຈະສາມາດເຂົ້າເຖິງ Grafana ຈາກ a web browser ໂດຍໃຊ້ທີ່ຢູ່ IP ຂອງເຊີບເວີ Ubuntu ທີ່ຕິດຕັ້ງຊອບແວທັງໝົດ.
ມີຂໍ້ຜິດພາດເລັກນ້ອຍໃນ Grafana ທີ່ບໍ່ໃຫ້ທ່ານຕັ້ງລະຫັດຜ່ານເລີ່ມຕົ້ນໃຫມ່. ໃຊ້ຂັ້ນຕອນເຫຼົ່ານີ້ຖ້າທ່ານພົບບັນຫານີ້.
ຂັ້ນຕອນທີ່ຕ້ອງເຮັດໃນເຊີບເວີ Ubuntu ເພື່ອຕັ້ງລະຫັດຜ່ານໃນ Grafana:
- ໄປທີ່ /var/lib/grafana/grafana.db
- ຕິດຕັ້ງ sqllite3
o sudo apt ຕິດຕັ້ງ sqlite3 - ດໍາເນີນການຄໍາສັ່ງນີ້ຢູ່ໃນ terminal ຂອງທ່ານ
o sqlite3 grafana.db - ຄໍາສັ່ງ Sqlite ເປີດ; ດໍາເນີນການສອບຖາມຕໍ່ໄປນີ້:
>ລຶບຈາກຜູ້ໃຊ້ທີ່ເຂົ້າສູ່ລະບົບ='admin' - restart grafana ແລະພິມ admin ເປັນຊື່ຜູ້ໃຊ້ແລະລະຫັດຜ່ານ. ມັນກະຕຸ້ນໃຫ້ມີລະຫັດຜ່ານໃຫມ່.
ເມື່ອຊອບແວທັງຫມົດຖືກຕິດຕັ້ງ, ສ້າງໄຟລ໌ config ໃນ Telegraf ເຊິ່ງຈະຊ່ວຍດຶງຂໍ້ມູນ telemetry ຈາກສະວິດແລະຍູ້ມັນໄປ InuxDB.
Openconfig Sensor Plugin
ໃນເຊີບເວີ Ubuntu, ແກ້ໄຂໄຟລ໌ /etc/telegraf/telegraf.conf ເພື່ອເພີ່ມທຸກສິ່ງທີ່ຕ້ອງການ. plugins ແລະເຊັນເຊີ. ສໍາລັບ openconfig sensors, ພວກເຮົາໃຊ້ plugin gNMI ທີ່ສະແດງຢູ່ໃນຮູບ 6. ສໍາລັບຈຸດປະສົງການສາທິດ, ເພີ່ມ hostname ເປັນ "spine1", ເລກພອດ "50051" ທີ່ໃຊ້ສໍາລັບ gRPC, ຊື່ຜູ້ໃຊ້ແລະລະຫັດຜ່ານຂອງສະຫຼັບ, ແລະຕົວເລກ. ຂອງວິນາທີສໍາລັບການ redial ໃນກໍລະນີຂອງຄວາມລົ້ມເຫຼວ.
ໃນ stanza ສະຫມັກ, ເພີ່ມຊື່ທີ່ເປັນເອກະລັກ, "cpu" ສໍາລັບເຊັນເຊີສະເພາະນີ້, ເສັ້ນທາງເຊັນເຊີ, ແລະໄລຍະເວລາສໍາລັບການຈັບຂໍ້ມູນນີ້ຈາກສະຫຼັບ. ເພີ່ມ plugin ດຽວກັນ inputs.gnmi ແລະ inputs.gnmi.subscription ສໍາລັບເຊັນເຊີ config ເປີດທັງຫມົດ. (ຮູບ 6)

ປລັກອິນເຊັນເຊີເດີມ
ນີ້ແມ່ນປລັກອິນອິນເຕີເຟຊະ telemetry Juniper ທີ່ໃຊ້ສໍາລັບເຊັນເຊີພື້ນເມືອງ. ໃນໄຟລ໌ telegraf.conf ດຽວກັນ, ໃຫ້ເພີ່ມ plugin sensor native inputs.jti_openconfig_telemetry ທີ່ຊ່ອງຂໍ້ມູນເກືອບຄືກັນກັບ openconfig. ໃຊ້ ID ລູກຄ້າທີ່ເປັນເອກະລັກສໍາລັບທຸກໆເຊັນເຊີ; ທີ່ນີ້, ພວກເຮົາໃຊ້ "telegraf3". ຊື່ທີ່ເປັນເອກະລັກທີ່ໃຊ້ຢູ່ນີ້ສໍາລັບເຊັນເຊີນີ້ແມ່ນ "mem" (ຮູບ 7).

ສຸດທ້າຍ, ເພີ່ມປລັກອິນຜົນຜະລິດ outputs.influxdb ເພື່ອສົ່ງຂໍ້ມູນເຊັນເຊີນີ້ໄປຫາ InfluxDB. ທີ່ນີ້, ຖານຂໍ້ມູນມີຊື່ວ່າ "telegraf" ທີ່ມີຊື່ຜູ້ໃຊ້ເປັນ "influx" ແລະລະຫັດຜ່ານ "influxdb" (ຮູບ 8).

ເມື່ອທ່ານໄດ້ແກ້ໄຂໄຟລ໌ telegraf.conf ແລ້ວ, ໃຫ້ເປີດບໍລິການ telegraf ຄືນໃໝ່. ຕອນນີ້, ໃຫ້ກວດເບິ່ງໃນ InfluxDB CLI ເພື່ອໃຫ້ແນ່ໃຈວ່າການວັດແທກຖືກສ້າງຂື້ນສໍາລັບເຊັນເຊີທີ່ເປັນເອກະລັກທັງຫມົດ. ພິມ “influx” ເພື່ອເຂົ້າໄປໃນ InfluxDB CLI.

ດັ່ງທີ່ເຫັນໃນຮູບ. 9, ໃສ່ influxDB prompt ແລະໃຊ້ຖານຂໍ້ມູນ "telegraf". ທຸກໆຊື່ທີ່ເປັນເອກະລັກໃຫ້ກັບເຊັນເຊີຖືກລະບຸໄວ້ເປັນການວັດແທກ.
ເພື່ອເບິ່ງຜົນໄດ້ຮັບຂອງການວັດແທກຫນຶ່ງ, ພຽງແຕ່ໃຫ້ແນ່ໃຈວ່າໄຟລ໌ telegraf ຖືກຕ້ອງແລະເຊັນເຊີເຮັດວຽກ, ໃຊ້ຄໍາສັ່ງ "ເລືອກ * ຈາກ cpu limit 1" ດັ່ງທີ່ສະແດງຢູ່ໃນຮູບ 10.

ທຸກໆຄັ້ງທີ່ມີການປ່ຽນແປງຕໍ່ກັບໄຟລ໌ telegraf.conf, ໃຫ້ແນ່ໃຈວ່າໄດ້ຢຸດ InuxDB, ຣີສະຕາດ Telegraf, ແລະຈາກນັ້ນເລີ່ມ InuxDB.
ເຂົ້າສູ່ລະບົບ Grafana ຈາກຕົວທ່ອງເວັບແລະສ້າງ dashboards ຫຼັງຈາກຮັບປະກັນວ່າຂໍ້ມູນຈະຖືກເກັບກໍາຢ່າງຖືກຕ້ອງ.
ໄປທີ່ການເຊື່ອມຕໍ່> InfuxDB> ເພີ່ມແຫຼ່ງຂໍ້ມູນໃຫມ່.

- ຕັ້ງຊື່ໃຫ້ແຫຼ່ງຂໍ້ມູນນີ້. ໃນຕົວຢ່າງນີ້ແມ່ນ "test-1".
- ພາຍໃຕ້ HTTP stanza, ໃຊ້ Ubuntu server IP ແລະ 8086 port.

- ໃນລາຍລະອຽດຂອງ InfluxDB, ໃຊ້ຊື່ຖານຂໍ້ມູນດຽວກັນ, "telegraf," ແລະໃຫ້ຊື່ຜູ້ໃຊ້ແລະລະຫັດຜ່ານຂອງເຄື່ອງແມ່ຂ່າຍ Ubuntu.
- ກົດ Save & test. ໃຫ້ແນ່ໃຈວ່າທ່ານເຫັນຂໍ້ຄວາມ, "ປະສົບຜົນສໍາເລັດ".

- ເມື່ອແຫຼ່ງຂໍ້ມູນໄດ້ຖືກເພີ່ມຢ່າງສໍາເລັດຜົນ, ໄປທີ່ Dashboards ແລະຄລິກໃຫມ່. ໃຫ້ພວກເຮົາສ້າງ dashboards ຈໍານວນຫນ້ອຍທີ່ຈໍາເປັນສໍາລັບການເຮັດວຽກຂອງ AI / ML ໃນໂຫມດບັນນາທິການ.
Examples ຂອງ Sensor Graphs
ຕໍ່ໄປນີ້ແມ່ນ examples ຂອງເຄົາເຕີທີ່ສໍາຄັນຈໍານວນຫນຶ່ງທີ່ມີຄວາມຈໍາເປັນສໍາລັບການຕິດຕາມເຄືອຂ່າຍ AI/ML.
ເປີເຊັນtage ການນໍາໃຊ້ສໍາລັບການໂຕ້ຕອບ ingress et-0/0/0 ກ່ຽວກັບກະດູກສັນຫຼັງ-1

- ເລືອກແຫຼ່ງຂໍ້ມູນເປັນ test-1.
- ໃນພາກ FROM, ເລືອກການວັດແທກເປັນ "ການໂຕ້ຕອບ". ນີ້ແມ່ນຊື່ສະເພາະທີ່ໃຊ້ສໍາລັບເສັ້ນທາງເຊັນເຊີນີ້.
- ໃນພາກ WHERE, ເລືອກອຸປະກອນ::tag, ແລະໃນ tag ຄ່າ, ເລືອກ hostname ຂອງສະຫຼັບ, ນັ້ນແມ່ນ, spine1.
- ໃນພາກ SELECT, ເລືອກສາຂາເຊັນເຊີທີ່ທ່ານຕ້ອງການທີ່ຈະຕິດຕາມກວດກາ; ໃນກໍລະນີນີ້ເລືອກ “field(/interfaces/interface[if_name='et-0/0/0']/state/counters/if_in_1s_octes)”. ໃນປັດຈຸບັນຢູ່ໃນພາກດຽວກັນ, ໃຫ້ຄລິກໃສ່ "+" ແລະເພີ່ມຄະນິດສາດການຄິດໄລ່ນີ້ (/50000000000 * 100). ພວກເຮົາກໍາລັງຄິດໄລ່ໂດຍພື້ນຖານແລ້ວ percentage ການນໍາໃຊ້ການໂຕ້ຕອບ 400G.
- ໃຫ້ແນ່ໃຈວ່າ FORMAT ແມ່ນ "ຊຸດເວລາ," ແລະຕັ້ງຊື່ກຣາຟໃນສ່ວນ ALIAS.
 ການຄອບຄອງສູງສຸດສຳລັບຄິວໃດນຶ່ງ
ການຄອບຄອງສູງສຸດສຳລັບຄິວໃດນຶ່ງ

- ເລືອກແຫຼ່ງຂໍ້ມູນເປັນ test-1.
- ໃນພາກ FROM, ເລືອກການວັດແທກເປັນ "buffer."
- ໃນພາກ WHERE, ມີສາມຊ່ອງໃຫ້ຕື່ມ. ເລືອກອຸປະກອນ::tag, ແລະໃນ tag ຄ່າເລືອກ hostname ຂອງສະຫຼັບ (ie spine-1); ແລະເລືອກ /cos/interfaces/interface/@name::tag ແລະເລືອກການໂຕ້ຕອບ (ie et- 0/0/0); ແລະເລືອກຄິວເຊັ່ນກັນ, /cos/interfaces/interface/queues/queue/@queue::tag ແລະເລືອກແຖວທີ 4.
- ໃນພາກ SELECT, ເລືອກສາຂາເຊັນເຊີທີ່ທ່ານຕ້ອງການທີ່ຈະຕິດຕາມກວດກາ; ໃນກໍລະນີນີ້ເລືອກ "field(/cos/interfaces/interface/queues/queue/PeakBuferOccupancy)."
- ໃຫ້ແນ່ໃຈວ່າ FORMAT ແມ່ນ "ຊຸດເວລາ" ແລະຕັ້ງຊື່ກຣາຟໃນສ່ວນ ALIAS.
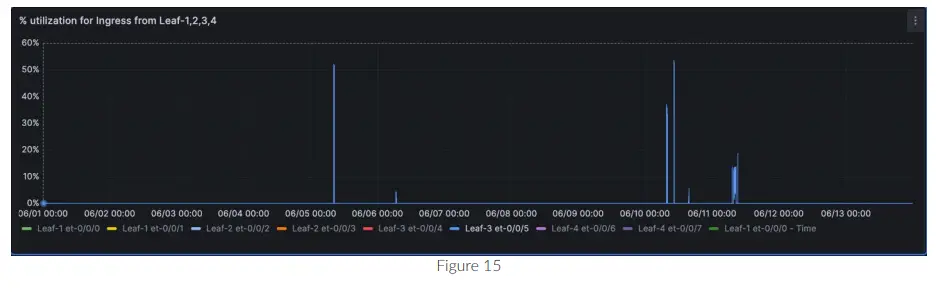
ທ່ານສາມາດລວບລວມຂໍ້ມູນສໍາລັບການໂຕ້ຕອບຫຼາຍອັນໃນກາຟດຽວກັນດັ່ງທີ່ເຫັນໃນຮູບ 17 ສໍາລັບ et-0/0/0, et-0/0/1, et-0/0/2 ແລະອື່ນໆ.

PFC ແລະ ECN ຫມາຍເຖິງອະນຸພັນ

ສໍາລັບການຊອກຫາຕົວແປສະເລ່ຍ (ຄວາມແຕກຕ່າງຂອງມູນຄ່າພາຍໃນໄລຍະເວລາ), ໃຫ້ໃຊ້ຮູບແບບການສອບຖາມດິບ.
ນີ້ແມ່ນການສອບຖາມ influx ທີ່ພວກເຮົາໄດ້ໃຊ້ເພື່ອຊອກຫາຄ່າສະເລ່ຍລະຫວ່າງສອງຄ່າ PFC ໃນ et-0/0/0 ຂອງ Spine-1 ໃນວິນາທີ.
SELECT derivative(mean(“/interfaces/interface[if_name='et-0/0/0′]/state/pfc-counter/tx_pkts”), 1s) ຈາກ “ການໂຕ້ຕອບ” ຢູ່ໃສ (“ອຸປະກອນ”::tag = 'Spine-1') ແລະ $timeFilter GROUP ຕາມເວລາ($interval)

SELECT derivative(mean(“/interfaces/interface[if_name='et-0/0/8′]/state/error-counters/ecn_ce_marked_pkts”), 1s) ຈາກ “ການໂຕ້ຕອບ” ຢູ່ໃສ (“ອຸປະກອນ”::tag = 'Spine-1') ແລະ $timeFilter GROUP ຕາມເວລາ($interval)

ການປ້ອນຂໍ້ມູນຜິດພາດ ໝາຍເຖິງ derivative

ການສອບຖາມດິບສໍາລັບຄວາມຜິດພາດຂອງຊັບພະຍາກອນຫມາຍຄວາມວ່າ derivative ແມ່ນ:
SELECT derivative(mean(“/interfaces/interface[if_name='et-0/0/0′]/state/error-counters/if_in_resource_errors”), 1s) ຈາກ “ການໂຕ້ຕອບ” ຢູ່ໃສ (“ອຸປະກອນ”::tag = 'Spine-1') ແລະ $timeFilter GROUP ຕາມເວລາ($interval)

ການຢອດຫາງຫມາຍເຖິງອະນຸພັນ

ການສອບຖາມດິບສໍາລັບການຢອດຫາງຫມາຍຄວາມວ່າ derivative ແມ່ນ:
SELECT derivative(mean(“/cos/interfaces/interface/queues/queue/tailDropBytes”), 1s) ຈາກ “buffer” ບ່ອນໃດ (“ອຸປະກອນ”::tag = 'Leaf-1' ແລະ “/cos/interfaces/interface/@name”::tag = 'et-0/0/0' ແລະ “/cos/interfaces/interface/queues/queue/@queue”::tag = '4') ແລະ $timeFilter GROUP ຕາມເວລາ($__interval) ຕື່ມ(null)
ການນໍາໃຊ້ CPU

- ເລືອກແຫຼ່ງຂໍ້ມູນເປັນ test-1.
- ໃນພາກ FROM, ເລືອກການວັດແທກເປັນ "newcpu"
- ໃນບ່ອນນັ້ນ, ມີສາມຊ່ອງໃຫ້ຕື່ມ. ເລືອກອຸປະກອນ::tag ແລະໃນ tag value ເລືອກ hostname ຂອງ switch (ie spine-1). ແລະໃນ /components/component/properties/property/name:tag, ແລະເລືອກ cpuutilization-total AND ໃນຊື່::tag ເລືອກ RE0.
- ໃນສ່ວນ SELECT, ເລືອກສາຂາເຊັນເຊີທີ່ທ່ານຕ້ອງການທີ່ຈະຕິດຕາມ. ໃນກໍລະນີນີ້, ເລືອກເອົາ "ພາກສະຫນາມ (ລັດ / ມູນຄ່າ)".

ຄໍາຖາມດິບສໍາລັບການຊອກຫາຕົວອະນຸພັນທີ່ບໍ່ແມ່ນລົບຂອງຫາງຫຼຸດລົງສໍາລັບການສະຫຼັບຫຼາຍໃນການໂຕ້ຕອບຫຼາຍໃນ bits/sec.
SELECT non_negative_derivative(mean(“/cos/interfaces/interface/queues/queue/tailDropBytes”), 1s)*8 ຈາກ “buffer” ຢູ່ໃສ (ອຸປະກອນ::tag =~ /^Spine-[1-2]$/) ແລະ (“/cos/interfaces/interface/@name”::tag =~ /et-0\/0\/[0-9]/ ຫຼື “/cos/interfaces/interface/@name”::tag=~/et-0\/0\/1[0-5]/) ແລະ $timeFilter GROUP ຕາມເວລາ($__interval), ອຸປະກອນ::tag ຕື່ມ (null)

ເຫຼົ່ານີ້ແມ່ນບາງສ່ວນຂອງ examples ຂອງກາຟທີ່ສາມາດສ້າງໄດ້ສໍາລັບການຕິດຕາມກວດກາເຄືອຂ່າຍ AI/ML.
ສະຫຼຸບ
ເອກະສານສະບັບນີ້ສະແດງໃຫ້ເຫັນວິທີການດຶງຂໍ້ມູນ telemetry ແລະການເບິ່ງເຫັນມັນໂດຍການສ້າງກາຟ. ເອກະສານສະບັບນີ້ເວົ້າສະເພາະກ່ຽວກັບເຊັນເຊີ AI/ML, ທັງແບບພື້ນເມືອງ ແລະແບບເປີດ, ແຕ່ການຕັ້ງຄ່າສາມາດນຳໃຊ້ໄດ້ກັບເຊັນເຊີທຸກປະເພດ. ພວກເຮົາຍັງໄດ້ລວມເອົາວິທີແກ້ໄຂສໍາລັບບັນຫາຫຼາຍຢ່າງທີ່ທ່ານອາດຈະປະເຊີນໃນຂະນະທີ່ສ້າງການຕິດຕັ້ງ. ຂັ້ນຕອນແລະຜົນໄດ້ຮັບທີ່ອະທິບາຍໃນເອກະສານນີ້ແມ່ນສະເພາະກັບສະບັບຂອງ TIG stack ທີ່ກ່າວມາກ່ອນຫນ້ານີ້. ມັນອາດມີການປ່ຽນແປງຂຶ້ນກັບລຸ້ນຂອງຊອບແວ, ເຊັນເຊີ ແລະລຸ້ນ Junos.
ເອກະສານອ້າງອີງ
Juniper Yang Data Model Explorer ສໍາລັບຕົວເລືອກເຊັນເຊີທັງໝົດ
https://apps.juniper.net/ydm-explorer/
Openconfig forum ສໍາລັບ openconfig sensors
https://www.openconfig.net/projects/models/
![]()
ສໍານັກງານໃຫຍ່ຂອງບໍລິສັດແລະການຂາຍ
Juniper Networks, Inc.
1133 ວິທີການປະດິດສ້າງ
Sunnyvale, CA 94089 USA
ໂທລະສັບ: 888. JUNIPER (888.586.4737)
ຫຼື +1.408.745.2000
ແຟັກ: +1.408.745.2100
www.juniper.net
APAC ແລະສໍານັກງານໃຫຍ່ EMEA
Juniper Networks International BV
Boeing Avenue 240
1119 PZ Schiphol-Rijk
Amsterdam, ເນເທີແລນ
ໂທລະສັບ: +31.207.125.700
ແຟັກ: +31.207.125.701
ລິຂະສິດ 2023 Juniper Networks. Inc. ສະຫງວນລິຂະສິດ. Juniper Networks, ສັນຍາລັກ Juniper Networks, Juniper, Junos, ແລະເຄື່ອງໝາຍການຄ້າອື່ນໆແມ່ນເຄື່ອງໝາຍການຄ້າທີ່ຈົດທະບຽນຂອງ Juniper Networks. Inc. ແລະ/ຫຼື ສາຂາໃນສະຫະລັດ ແລະປະເທດອື່ນໆ. ຊື່ອື່ນອາດຈະເປັນເຄື່ອງຫມາຍການຄ້າຂອງເຈົ້າຂອງຂອງເຂົາເຈົ້າ. Juniper Networks ບໍ່ຮັບຜິດຊອບຕໍ່ຄວາມບໍ່ຖືກຕ້ອງໃດໆໃນເອກະສານນີ້. Juniper Networks ສະຫງວນສິດໃນການປ່ຽນແປງ. ປັບປຸງແກ້ໄຂ. ໂອນ, ຫຼືແກ້ໄຂສິ່ງພິມນີ້ໂດຍບໍ່ໄດ້ແຈ້ງລ່ວງໜ້າ.
ສົ່ງຄຳຕິຊົມຫາ: design-center-comments@juniper.net V1.0/240807/ejm5-telemetry-junos-ai-ml
ເອກະສານ / ຊັບພະຍາກອນ
 |
Juniper NETWORKS Telemetry In Junos ສໍາລັບ AI ML Workloads Software [pdf] ຄູ່ມືຜູ້ໃຊ້ Telemetry In Junos ສໍາລັບ AI ML Workloads Software, Junos ສໍາລັບ AI ML Workloads Software, AI ML Workloads Software, Workloads Software, Software |