NVIDIA NeMo Framework

លក្ខណៈបច្ចេកទេស
- ឈ្មោះផលិតផល៖ NVIDIA NeMo Framework
- វេទិកាដែលរងផលប៉ះពាល់៖ វីនដូ, លីនុច, macOS
- កំណែដែលរងផលប៉ះពាល់៖ កំណែទាំងអស់មុន 24
- ភាពងាយរងគ្រោះផ្នែកសុវត្ថិភាព៖ CVE-2025-23360
- ពិន្ទុមូលដ្ឋានវាយតម្លៃហានិភ័យ៖ 7.1 (CVSS v3.1)
ការណែនាំអំពីការប្រើប្រាស់ផលិតផល
ការដំឡើងបច្ចុប្បន្នភាពសុវត្ថិភាព៖
ដើម្បីការពារប្រព័ន្ធរបស់អ្នក សូមអនុវត្តតាមជំហានទាំងនេះ៖
- ទាញយកការចេញផ្សាយចុងក្រោយបំផុតពីទំព័រ NeMo-Framework-Launcher Releases នៅលើ GitHub ។
- សូមចូលទៅកាន់ NVIDIA Product Security សម្រាប់ព័ត៌មានបន្ថែម។
ព័ត៌មានលម្អិតអំពីបច្ចុប្បន្នភាពសុវត្ថិភាព៖
ការធ្វើបច្ចុប្បន្នភាពសុវត្ថិភាពដោះស្រាយភាពងាយរងគ្រោះនៅក្នុង NVIDIA NeMo Framework ដែលអាចនាំទៅដល់ការប្រតិបត្តិកូដ និងទិន្នន័យ tampខ្សែអក្សរ
ធ្វើឱ្យប្រសើរកម្មវិធី:
ប្រសិនបើអ្នកកំពុងប្រើការចេញផ្សាយសាខាមុន វាត្រូវបានណែនាំឱ្យដំឡើងកំណែទៅការចេញផ្សាយសាខាចុងក្រោយបំផុត ដើម្បីដោះស្រាយបញ្ហាសុវត្ថិភាព។
ជាងview
NVIDIA NeMo Framework គឺជាក្របខណ្ឌ AI ជំនាន់ដើមដែលអាចធ្វើមាត្រដ្ឋានបាន និងបង្កើតឡើងសម្រាប់អ្នកស្រាវជ្រាវ និងអ្នកអភិវឌ្ឍន៍ដែលកំពុងធ្វើការលើ គំរូភាសាធំ, ពហុម៉ូដ, និង ការនិយាយ AI (ឧ ការទទួលស្គាល់ការនិយាយដោយស្វ័យប្រវត្តិ និង អត្ថបទទៅការនិយាយ) វាអនុញ្ញាតឱ្យអ្នកប្រើប្រាស់បង្កើត ប្ដូរតាមបំណង និងប្រើប្រាស់គំរូ AI ជំនាន់ថ្មីប្រកបដោយប្រសិទ្ធភាពដោយប្រើប្រាស់កូដដែលមានស្រាប់ និងចំណុចត្រួតពិនិត្យគំរូដែលបានបណ្តុះបណ្តាលជាមុន។
ការណែនាំអំពីការដំឡើង: ដំឡើង NeMo Framework
NeMo Framework ផ្តល់ការគាំទ្រពីចុងដល់ចប់សម្រាប់ការបង្កើតគំរូភាសាធំ (LLMs) និង Multimodal Models (MMs)។ វាផ្តល់នូវភាពបត់បែនក្នុងការប្រើក្នុងបរិវេណ មជ្ឈមណ្ឌលទិន្នន័យ ឬជាមួយអ្នកផ្តល់សេវាពពកដែលអ្នកពេញចិត្ត។ វាក៏គាំទ្រការប្រតិបត្តិលើបរិស្ថានដែលបានបើក SLURM ឬ Kubernetes ផងដែរ។

ការរៀបចំទិន្នន័យ
អ្នកថែរក្សា NeMo [1] គឺជាបណ្ណាល័យ Python ដែលរួមបញ្ចូលនូវសំណុំនៃម៉ូឌុលសម្រាប់ការជីកយករ៉ែទិន្នន័យ និងការបង្កើតទិន្នន័យសំយោគ។ ពួកវាអាចធ្វើមាត្រដ្ឋានបាន និងធ្វើឱ្យប្រសើរសម្រាប់ GPU ដែលធ្វើឱ្យពួកវាល្អសម្រាប់ការរៀបចំទិន្នន័យភាសាធម្មជាតិដើម្បីបណ្តុះបណ្តាល ឬកែសម្រួល LLMs ។ ជាមួយនឹង NeMo Curator អ្នកអាចទាញយកអត្ថបទដែលមានគុណភាពខ្ពស់ពីវត្ថុធាតុដើមយ៉ាងមានប្រសិទ្ធភាព web ប្រភពទិន្នន័យ។
ការបណ្តុះបណ្តាល និងការប្ដូរតាមបំណង
NeMo Framework ផ្តល់នូវឧបករណ៍សម្រាប់ការបណ្តុះបណ្តាលប្រកបដោយប្រសិទ្ធភាព និងការប្តូរតាមបំណង អិលអិលអេម និងម៉ូដែល Multimodal ។ វារួមបញ្ចូលការកំណត់លំនាំដើមសម្រាប់ការដំឡើងចង្កោមកុំព្យូទ័រ ការទាញយកទិន្នន័យ និងប៉ារ៉ាម៉ែត្រខ្ពស់នៃគំរូ ដែលអាចត្រូវបានកែតម្រូវដើម្បីហ្វឹកហាត់លើសំណុំទិន្នន័យ និងម៉ូដែលថ្មី។ បន្ថែមពីលើការបណ្តុះបណ្តាលមុន NeMo គាំទ្រទាំងបច្ចេកទេស Supervised Fine-Tuning (SFT) និង Parameter Efficient Fine-Tuning (PEFT) ដូចជា LoRA, Ptuning និងច្រើនទៀត។
មានជម្រើសពីរដើម្បីចាប់ផ្តើមការបណ្តុះបណ្តាលនៅក្នុង NeMo – ដោយប្រើ NeMo 2.0 API interface ឬជាមួយ NeMo Run។
- ជាមួយ NeMo Run (បានណែនាំ)៖ NeMo Run ផ្តល់នូវចំណុចប្រទាក់មួយដើម្បីសម្រួលការកំណត់រចនាសម្ព័ន្ធ ការប្រតិបត្តិ និងការគ្រប់គ្រងការពិសោធន៍លើបរិស្ថានកុំព្យូទ័រផ្សេងៗ។ នេះរួមបញ្ចូលទាំងការបើកដំណើរការការងារនៅលើស្ថានីយការងាររបស់អ្នកក្នុងស្រុក ឬនៅលើចង្កោមធំ – ទាំង SLURM បានបើកដំណើរការ ឬ Kubernetes នៅក្នុងបរិយាកាសពពក។
- ការបណ្តុះបណ្តាលមុន និង PEFT Quickstart ជាមួយ NeMo Run
- ការប្រើប្រាស់ NeMo 2.0 API៖ វិធីសាស្រ្តនេះដំណើរការបានយ៉ាងល្អជាមួយនឹងការដំឡើងដ៏សាមញ្ញដែលពាក់ព័ន្ធនឹងម៉ូដែលតូចៗ ឬប្រសិនបើអ្នកចាប់អារម្មណ៍ក្នុងការសរសេរកម្មវិធីផ្ទុកទិន្នន័យផ្ទាល់ខ្លួន រង្វិលជុំហ្វឹកហាត់ ឬផ្លាស់ប្តូរស្រទាប់គំរូ។ វាផ្តល់ឱ្យអ្នកនូវភាពបត់បែន និងការគ្រប់គ្រងលើការកំណត់រចនាសម្ព័ន្ធ និងធ្វើឱ្យវាងាយស្រួលក្នុងការពង្រីក និងកំណត់ការកំណត់តាមបំណងតាមកម្មវិធី។
-
ត្រាកំពុងដំណើរការ Quickstart ជាមួយ NeMo 2.0 API
-
ការផ្ទេរពី NeMo 1.0 ទៅ NeMo 2.0 API
-
ការតម្រឹម
- NeMo-Aligner [1] គឺជាកញ្ចប់ឧបករណ៍ដែលអាចធ្វើមាត្រដ្ឋានបានសម្រាប់ការតម្រឹមគំរូប្រកបដោយប្រសិទ្ធភាព។ កញ្ចប់ឧបករណ៍មានការគាំទ្រសម្រាប់ក្បួនដោះស្រាយការតម្រឹមគំរូដ៏ទំនើបដូចជា SteerLM, DPO, ការពង្រឹងការរៀនពីមតិយោបល់របស់មនុស្ស (RLHF) និងច្រើនទៀត។ ក្បួនដោះស្រាយទាំងនេះអាចឱ្យអ្នកប្រើប្រាស់តម្រឹមគំរូភាសាឱ្យកាន់តែមានសុវត្ថិភាព មិនបង្កគ្រោះថ្នាក់ និងមានប្រយោជន៍។
- ចំណុចត្រួតពិនិត្យ NeMo-Aligner ទាំងអស់គឺត្រូវគ្នាជាមួយប្រព័ន្ធអេកូ NeMo ដែលអនុញ្ញាតឱ្យមានការប្ដូរតាមបំណង និងការដាក់ពង្រាយការសន្និដ្ឋានបន្ថែមទៀត។
ដំណើរការការងារជាជំហាន ៗ នៃដំណាក់កាលទាំងបីនៃ RLHF លើគំរូ GPT-2B តូចមួយ៖
- ការបណ្តុះបណ្តាល SFT
- ការបណ្តុះបណ្តាលគំរូរង្វាន់
- ការបណ្តុះបណ្តាល PPO
លើសពីនេះ យើងបង្ហាញការគាំទ្រចំពោះវិធីសាស្ត្រតម្រឹមប្រលោមលោកផ្សេងៗ៖
- DPO៖ ក្បួនដោះស្រាយការតម្រឹមទម្ងន់ស្រាលធៀបនឹង RLHF ជាមួយនឹងមុខងារបាត់បង់ដ៏សាមញ្ញជាង។
- ការលេងដោយខ្លួនឯង។ ការលៃតម្រូវការកែលម្អ (SPIN)
- SteerLM៖ បច្ចេកទេសផ្អែកលើលក្ខខណ្ឌ-SFT ជាមួយនឹងទិន្នផលដែលអាចគ្រប់គ្រងបាន។
សូមពិនិត្យមើលឯកសារសម្រាប់ព័ត៌មានបន្ថែម៖ ឯកសារតម្រឹម
ម៉ូដែលចម្រុះ
- NeMo Framework ផ្តល់នូវកម្មវិធីដែលប្រសើរឡើងដើម្បីបណ្តុះបណ្តាល និងដាក់ឱ្យប្រើប្រាស់នូវគំរូពហុម៉ូដទំនើបទាន់សម័យនៅទូទាំងប្រភេទមួយចំនួន៖ គំរូភាសាពហុម៉ូឌុល មូលដ្ឋានគ្រឹះនៃចក្ខុវិស័យ គំរូអត្ថបទទៅរូបភាព និងលើសពីជំនាន់ 2D ដោយប្រើ Neural Radiance Fields (NeRF)។
- ប្រភេទនីមួយៗត្រូវបានរចនាឡើងដើម្បីបំពេញតម្រូវការជាក់លាក់ និងភាពជឿនលឿនក្នុងវិស័យនេះ ដោយប្រើប្រាស់ម៉ូដែលទំនើបៗ ដើម្បីគ្រប់គ្រងប្រភេទទិន្នន័យជាច្រើន រួមទាំងអត្ថបទ រូបភាព និងគំរូ 3D។
ចំណាំ
យើងកំពុងផ្លាស់ប្តូរការគាំទ្រសម្រាប់ម៉ូដែលពហុម៉ូឌុលពី NeMo 1.0 ទៅ NeMo 2.0។ ប្រសិនបើអ្នកចង់រុករកដែននេះក្នុងពេលនេះ សូមមើលឯកសារសម្រាប់ការចេញផ្សាយ NeMo 24.07 (មុន)។
ការដាក់ពង្រាយ និងការសន្និដ្ឋាន
NeMo Framework ផ្តល់នូវផ្លូវជាច្រើនសម្រាប់ការសន្និដ្ឋាន LLM ដែលផ្តល់ដល់សេណារីយ៉ូនៃការដាក់ពង្រាយផ្សេងៗ និងតម្រូវការការអនុវត្ត។
ប្រើជាមួយ NVIDIA NIM
- NeMo Framework រួមបញ្ចូលគ្នាយ៉ាងរលូនជាមួយឧបករណ៍ដាក់ពង្រាយគំរូកម្រិតសហគ្រាសតាមរយៈ NVIDIA NIM ។ សមាហរណកម្មនេះត្រូវបានដំណើរការដោយ NVIDIA TensorRT-LLM ដែលធានាបាននូវប្រសិទ្ធភាព និងវិចារណញាណដែលអាចធ្វើមាត្រដ្ឋានបាន។
- សម្រាប់ព័ត៌មានបន្ថែមអំពី NIM សូមចូលទៅកាន់ NVIDIA webគេហទំព័រ។
ប្រើជាមួយ TensorRT-LLM ឬ vLLM
- NeMo Framework ផ្តល់នូវស្គ្រីប និង APIs ដើម្បីនាំចេញគំរូទៅកាន់បណ្ណាល័យដែលបង្កើនប្រសិទ្ធភាពការសន្និដ្ឋានចំនួនពីរ TensorRT-LLM និង vLLM និងដើម្បីដាក់ពង្រាយគំរូដែលបាននាំចេញជាមួយនឹង NVIDIA Triton Inference Server។
- សម្រាប់សេណារីយ៉ូដែលតម្រូវឱ្យមានការធ្វើឱ្យប្រសើរឡើង ម៉ូដែល NeMo អាចប្រើប្រាស់ TensorRT-LLM ជាបណ្ណាល័យឯកទេសសម្រាប់ការពន្លឿន និងបង្កើនប្រសិទ្ធភាពការសន្និដ្ឋាន LLM លើ NVIDIA GPUs ។ ដំណើរការនេះពាក់ព័ន្ធនឹងការបំប្លែងម៉ូដែល NeMo ទៅជាទម្រង់ដែលត្រូវគ្នាជាមួយ TensorRT-LLM ដោយប្រើម៉ូឌុល nemo.export ។
- ការដាក់ពង្រាយ LLM ចប់ហើយ។view
- ប្រើគំរូភាសាធំ NeMo ជាមួយ NIM
- ប្រើគំរូភាសាធំ NeMo ជាមួយ TensorRT-LLM
- ប្រើម៉ូដែលភាសាធំ NeMo ជាមួយ vLLM
ម៉ូដែលដែលគាំទ្រ
គំរូភាសាធំ
| គំរូភាសាធំ | ការហ្វឹកហាត់ និង SFT | PEFT | ការតម្រឹម | ការបង្រួបបង្រួមការបណ្តុះបណ្តាល FP8 | TRT/TRTLLM | បម្លែងទៅជា & ពីការឱបមុខ | ការវាយតម្លៃ |
|---|---|---|---|---|---|---|---|
| Llama3 8B/70B, Llama3.1 405B | បាទ | បាទ | x | បាទ / ចាស (បានផ្ទៀងផ្ទាត់ដោយផ្នែក) | បាទ | ទាំងពីរ | បាទ |
| ល្បាយ 8x7B/8x22B | បាទ | បាទ | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | បាទ | ទាំងពីរ | បាទ |
| Nemotron 3 8B | បាទ | x | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | x | ទាំងពីរ | បាទ |
| Nemotron 4 340B | បាទ | x | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | x | ទាំងពីរ | បាទ |
| Baichuan2 7B | បាទ | បាទ | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | x | ទាំងពីរ | បាទ |
| ChatGLM3 6B | បាទ | បាទ | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | x | ទាំងពីរ | បាទ |
| Gemma 2B/7B | បាទ | បាទ | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | បាទ | ទាំងពីរ | បាទ |
| Gemma2 2B/9B/27B | បាទ | បាទ | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | x | ទាំងពីរ | បាទ |
| Mamba2 130M/370M/780M/1.3B/2.7B/8B/ Hybrid-8B | បាទ | បាទ | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | x | x | បាទ |
| ភី ៣ មីនី ៤ គ | x | បាទ | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | x | x | x |
| Qwen2 0.5B/1.5B/7B/72B | បាទ | បាទ | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | បាទ | ទាំងពីរ | បាទ |
| StarCoder 15B | បាទ | បាទ | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | បាទ | ទាំងពីរ | បាទ |
| StarCoder2 3B/7B/15B | បាទ | បាទ | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | បាទ | ទាំងពីរ | បាទ |
| BERT 110M / 340M | បាទ | បាទ | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | x | ទាំងពីរ | x |
| T5 220M/3B/11B | បាទ | បាទ | x | x | x | x | x |
គំរូភាសាចក្ខុវិស័យ
| គំរូភាសាចក្ខុវិស័យ | ការហ្វឹកហាត់ និង SFT | PEFT | ការតម្រឹម | ការបង្រួបបង្រួមការបណ្តុះបណ្តាល FP8 | TRT/TRTLLM | បម្លែងទៅជា & ពីការឱបមុខ | ការវាយតម្លៃ |
|---|---|---|---|---|---|---|---|
| NeVA (LLaVA 1.5) | បាទ | បាទ | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | x | ពី | x |
| Llama 3.2 Vision 11B/90B | បាទ | បាទ | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | x | ពី | x |
| LLaVA បន្ទាប់ (LLaVA 1.6) | បាទ | បាទ | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | x | ពី | x |
ម៉ូដែលបង្កប់
| គំរូភាសាបង្កប់ | ការហ្វឹកហាត់ និង SFT | PEFT | ការតម្រឹម | ការបង្រួបបង្រួមការបណ្តុះបណ្តាល FP8 | TRT/TRTLLM | បម្លែងទៅជា & ពីការឱបមុខ | ការវាយតម្លៃ |
|---|---|---|---|---|---|---|---|
| SBERT 340M | បាទ | x | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | x | ទាំងពីរ | x |
| ឡាម៉ា 3.2 ការបង្កប់ 1B | បាទ | x | x | បាទ/ចាស (មិនទាន់បានផ្ទៀងផ្ទាត់) | x | ទាំងពីរ | x |
គំរូមូលនិធិពិភពលោក
| គំរូមូលនិធិពិភពលោក | ក្រោយការបណ្តុះបណ្តាល | ពន្លឿនការសន្និដ្ឋាន |
|---|---|---|
| Cosmos-1.0-Diffusion-Text2World-7B | បាទ | បាទ |
| Cosmos-1.0-Diffusion-Text2World-14B | បាទ | បាទ |
| Cosmos-1.0-Diffusion-Video2World-7B | មកដល់ឆាប់ៗនេះ | មកដល់ឆាប់ៗនេះ |
| Cosmos-1.0-Diffusion-Video2World-14B | មកដល់ឆាប់ៗនេះ | មកដល់ឆាប់ៗនេះ |
| Cosmos-1.0-Autoregressive-4B | បាទ | បាទ |
| Cosmos-1.0-Autoregressive-Video2World-5B | មកដល់ឆាប់ៗនេះ | មកដល់ឆាប់ៗនេះ |
| Cosmos-1.0-Autoregressive-12B | បាទ | បាទ |
| Cosmos-1.0-Autoregressive-Video2World-13B | មកដល់ឆាប់ៗនេះ | មកដល់ឆាប់ៗនេះ |
ចំណាំ
NeMo ក៏គាំទ្រការហ្វឹកហាត់ជាមុនសម្រាប់ទាំងស្ថាបត្យកម្មនៃការសាយភាយ និងស្ថាបត្យកម្មស្វ័យប្រវត្តិ text2world ម៉ូដែលគ្រឹះ។
ការនិយាយ AI
ការបង្កើតគំរូសន្ទនា AI គឺជាដំណើរការដ៏ស្មុគស្មាញមួយដែលពាក់ព័ន្ធនឹងការកំណត់ បង្កើត និងបណ្តុះបណ្តាលគំរូនៅក្នុងដែនជាក់លាក់។ ដំណើរការនេះជាធម្មតាតម្រូវឱ្យធ្វើម្តងទៀតជាច្រើនដង ដើម្បីឈានដល់កម្រិតខ្ពស់នៃភាពត្រឹមត្រូវ។ ជារឿយៗវាពាក់ព័ន្ធនឹងការធ្វើឡើងវិញច្រើនដង ដើម្បីសម្រេចបាននូវភាពត្រឹមត្រូវខ្ពស់ ការកែសម្រួលយ៉ាងល្អិតល្អន់លើកិច្ចការផ្សេងៗ និងទិន្នន័យជាក់លាក់នៃដែន ធានានូវការអនុវត្តការបណ្តុះបណ្តាល និងការរៀបចំគំរូសម្រាប់ការដាក់ពង្រាយការសន្និដ្ឋាន។
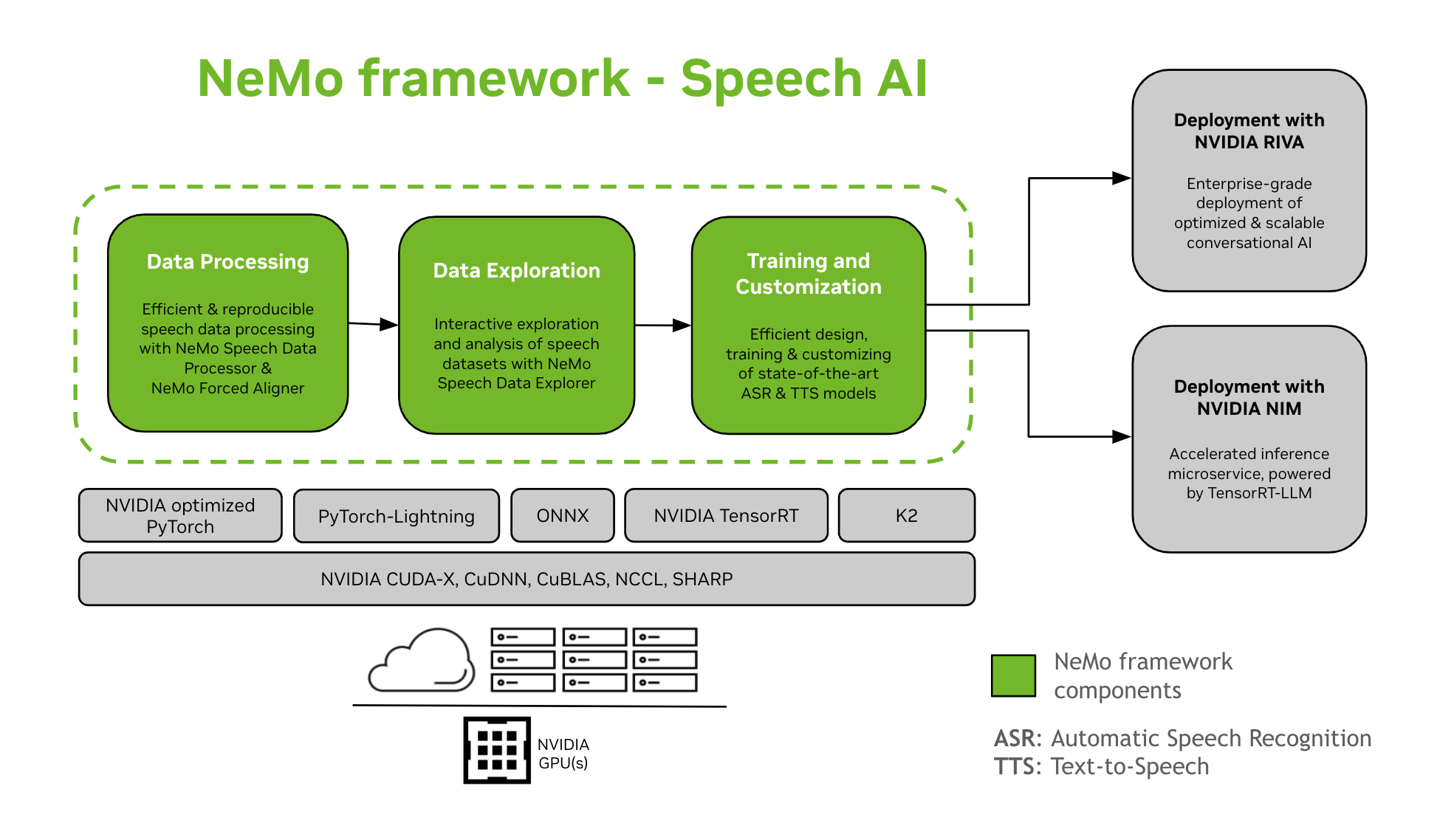
NeMo Framework ផ្តល់ការគាំទ្រសម្រាប់ការបណ្តុះបណ្តាល និងការប្ដូរតាមបំណងនៃគំរូ Speech AI ។ នេះរួមបញ្ចូលទាំងកិច្ចការដូចជា ការទទួលស្គាល់ការនិយាយដោយស្វ័យប្រវត្តិ (ASR) និងការសំយោគអត្ថបទទៅការនិយាយ (TTS) ។ វាផ្តល់នូវការផ្លាស់ប្តូរយ៉ាងរលូនទៅកាន់ការដាក់ពង្រាយផលិតកម្មកម្រិតសហគ្រាសជាមួយ NVIDIA Riva ។ ដើម្បីជួយអ្នកអភិវឌ្ឍន៍ និងអ្នកស្រាវជ្រាវ NeMo Framework រួមបញ្ចូលនូវចំណុចត្រួតពិនិត្យដែលបានទទួលការបណ្តុះបណ្តាលជាមុន ដែលទំនើបបំផុត ឧបករណ៍សម្រាប់ដំណើរការទិន្នន័យការនិយាយដែលអាចផលិតឡើងវិញបាន និងលក្ខណៈពិសេសសម្រាប់ការរុករកអន្តរកម្ម និងការវិភាគនៃសំណុំទិន្នន័យការនិយាយ។ សមាសធាតុនៃ NeMo Framework សម្រាប់ Speech AI មានដូចខាងក្រោម៖
ការបណ្តុះបណ្តាល និងការប្ដូរតាមបំណង
NeMo Framework មានអ្វីគ្រប់យ៉ាងដែលត្រូវការដើម្បីបណ្តុះបណ្តាល និងប្ដូរគំរូការនិយាយតាមបំណង (ASR, ចំណាត់ថ្នាក់នៃការនិយាយ, ការទទួលស្គាល់វាគ្មិន, ការបញ្ចេញសំឡេងរបស់វាគ្មិន, និង TTS) តាមរបៀបដែលអាចបន្តពូជបាន។
SOTA គំរូដែលបានបណ្តុះបណ្តាលជាមុន
- NeMo Framework ផ្តល់នូវរូបមន្តទំនើប និងកន្លែងត្រួតពិនិត្យមុនការបណ្តុះបណ្តាលមួយចំនួន ASR និង TTS ម៉ូដែល ក៏ដូចជាការណែនាំអំពីរបៀបផ្ទុកពួកវា។
- ឧបករណ៍និយាយ
- NeMo Framework ផ្តល់នូវសំណុំឧបករណ៍ដែលមានប្រយោជន៍សម្រាប់ការបង្កើតគំរូ ASR និង TTS រួមទាំង៖
- NeMo Forced Aligner (NFA) សម្រាប់ការបង្កើត token-, word- និង segment-level timesestamps នៃការនិយាយនៅក្នុងអូឌីយ៉ូដោយប្រើប្រាស់គំរូនៃការទទួលស្គាល់ការនិយាយដោយស្វ័យប្រវត្តិដែលមានមូលដ្ឋានលើ CTC របស់ NeMo ។
- ឧបករណ៍ដំណើរការទិន្នន័យការនិយាយ (SDP)កញ្ចប់ឧបករណ៍សម្រាប់សម្រួលដំណើរការទិន្នន័យការនិយាយ។ វាអនុញ្ញាតឱ្យអ្នកតំណាងឱ្យប្រតិបត្តិការដំណើរការទិន្នន័យនៅក្នុងការកំណត់រចនាសម្ព័ន្ធមួយ។ fileកាត់បន្ថយកូដ boilerplate និងអនុញ្ញាតឱ្យផលិតឡើងវិញ និងចែករំលែក។
- Speech Data Explorer (SDE)ដែលផ្អែកលើ Dash web កម្មវិធីសម្រាប់ការរុករកអន្តរកម្ម និងការវិភាគនៃសំណុំទិន្នន័យការនិយាយ។
- ឧបករណ៍បង្កើតសំណុំទិន្នន័យ ដែលផ្តល់មុខងារដើម្បីតម្រឹមសំឡេងវែង files ជាមួយនឹងប្រតិចារិកដែលត្រូវគ្នា ហើយបំបែកវាទៅជាបំណែកខ្លីៗដែលសមរម្យសម្រាប់ការបណ្តុះបណ្តាលគំរូនៃការទទួលស្គាល់ការនិយាយដោយស្វ័យប្រវត្តិ (ASR) ។
- ឧបករណ៍ប្រៀបធៀប សម្រាប់ ASR Models ដើម្បីប្រៀបធៀបការព្យាករណ៍នៃគំរូ ASR ផ្សេងៗគ្នានៅកម្រិតភាពត្រឹមត្រូវនៃពាក្យ និងការបញ្ចេញសំឡេង។
- អ្នកវាយតម្លៃ ASR សម្រាប់ការវាយតម្លៃដំណើរការនៃម៉ូដែល ASR និងមុខងារផ្សេងទៀតដូចជាការរកឃើញសកម្មភាពសំឡេង។
- ឧបករណ៍ធ្វើឱ្យអត្ថបទធម្មតា។ សម្រាប់បំប្លែងអត្ថបទពីទម្រង់សរសេរទៅជាទម្រង់និយាយ និងច្រាសមកវិញ (ឧទាហរណ៍ “ថ្ងៃទី៣១” ទល់នឹង “សាមសិបដំបូង”)។
- ផ្លូវទៅកាន់ការដាក់ពង្រាយ
- ម៉ូដែល NeMo ដែលត្រូវបានបណ្តុះបណ្តាល ឬប្ដូរតាមបំណងដោយប្រើ NeMo Framework អាចត្រូវបានធ្វើឱ្យប្រសើរ និងដាក់ឱ្យប្រើប្រាស់ជាមួយ NVIDIA Riva ។ Riva ផ្តល់នូវកុងតឺន័រ និងគំនូសតាង Helm ដែលត្រូវបានរចនាឡើងជាពិសេសដើម្បីធ្វើស្វ័យប្រវត្តិកម្មជំហានសម្រាប់ការដាក់ពង្រាយប៊ូតុងរុញ។
ធនធានផ្សេងទៀត។
- ណេម៉ូ៖ ឃ្លាំងសំខាន់សម្រាប់ NeMo Framework
- ណេម៉ូ–រត់៖ ឧបករណ៍សម្រាប់កំណត់រចនាសម្ព័ន្ធ បើកដំណើរការ និងគ្រប់គ្រងការពិសោធន៍រៀនម៉ាស៊ីនរបស់អ្នក។
- NeMo-Aligner៖ កញ្ចប់ឧបករណ៍ដែលអាចធ្វើមាត្រដ្ឋានបានសម្រាប់ការតម្រឹមគំរូប្រកបដោយប្រសិទ្ធភាព
- NeMo-Curator៖ កញ្ចប់ឧបករណ៍សម្រាប់ដំណើរការ និងរៀបចំទិន្នន័យជាមុនដែលអាចធ្វើមាត្រដ្ឋានបានសម្រាប់ LLMs
ចូលរួមជាមួយសហគមន៍ NeMo សួរសំណួរ ទទួលបានការគាំទ្រ ឬរាយការណ៍កំហុស។
- ការពិភាក្សា NeMo
- បញ្ហា NeMo
ភាសាសរសេរកម្មវិធី និងក្របខ័ណ្ឌ
- ពស់ថ្លាន់៖ ចំណុចប្រទាក់ចម្បងដើម្បីប្រើ NeMo Framework
- ភីធរច៖ NeMo Framework ត្រូវបានបង្កើតឡើងនៅលើកំពូលនៃ PyTorch
អាជ្ញាប័ណ្ណ
- NeMo Github repo ត្រូវបានផ្តល់អាជ្ញាប័ណ្ណក្រោមអាជ្ញាប័ណ្ណ Apache 2.0
- NeMo Framework ត្រូវបានផ្តល់អាជ្ញាប័ណ្ណក្រោមកិច្ចព្រមព្រៀងផលិតផល NVIDIA AI ។ តាមរយៈការទាញ និងប្រើប្រាស់កុងតឺន័រ អ្នកទទួលយកលក្ខខណ្ឌនៃអាជ្ញាប័ណ្ណនេះ។
- កុងតឺន័រ NeMo Framework មានសម្ភារ Llama ដែលគ្រប់គ្រងដោយកិច្ចព្រមព្រៀងអាជ្ញាប័ណ្ណសហគមន៍ Meta Llama3 ។
លេខយោង
បច្ចុប្បន្ន ការគាំទ្រ NeMo Curator និង NeMo Aligner សម្រាប់ម៉ូដែល Multimodal គឺជាការងារដែលកំពុងដំណើរការ ហើយនឹងមានក្នុងពេលឆាប់ៗនេះ។
សំណួរគេសួរញឹកញាប់
សំណួរ៖ តើខ្ញុំអាចពិនិត្យមើលថាតើប្រព័ន្ធរបស់ខ្ញុំត្រូវបានប៉ះពាល់ដោយភាពងាយរងគ្រោះដោយរបៀបណា?
A: អ្នកអាចពិនិត្យមើលថាតើប្រព័ន្ធរបស់អ្នកត្រូវបានប៉ះពាល់ដោយការផ្ទៀងផ្ទាត់កំណែនៃ NVIDIA NeMo Framework ដែលបានដំឡើងឬអត់។ ប្រសិនបើវាស្ថិតនៅក្រោមកំណែ 24 ប្រព័ន្ធរបស់អ្នកអាចងាយរងគ្រោះ។
សំណួរ៖ តើអ្នកណាបានរាយការណ៍អំពីបញ្ហាសុវត្ថិភាព CVE-2025-23360?
A: បញ្ហាសន្តិសុខត្រូវបានរាយការណ៍ដោយ Or Peles – JFrog Security ។ NVIDIA ទទួលស្គាល់ការរួមចំណែករបស់ពួកគេ។
សំណួរ៖ តើខ្ញុំអាចទទួលបានការជូនដំណឹងអំពីព្រឹត្តិបត្រសុវត្ថិភាពនាពេលអនាគតដោយរបៀបណា?
ចម្លើយ៖ ចូលទៅកាន់ទំព័រសុវត្ថិភាពផលិតផល NVIDIA ដើម្បីជាវការជូនដំណឹងអំពីព្រឹត្តិបត្រសុវត្ថិភាព និងបន្តជូនដំណឹងអំពីបច្ចុប្បន្នភាពសុវត្ថិភាពផលិតផល។
ឯកសារ/ធនធាន
 |
NVIDIA NeMo Framework [pdf] ការណែនាំអ្នកប្រើប្រាស់ NeMo Framework, NeMo, Framework |